Learning Multimodal Violence Detection under Weak Supervision
Not only look, but also listen: Learning multimodal violence detection under weak supervision
暴力视频检测方向论文
💡 We introduce a HL-Net to simultaneously capture long-range relations and
local distance relations, of which these two relations are based on similarity prior and proximity prior, respectively三个并行的branch捕捉视频片段和集成的特征之间的不同联系:
- holistic branch captures long-range dependencies using similarity prior,
- localized branch captures local positional relation using proximity prior,
- score branch dynamically captures the closeness of predicted score.
相关工作,其中attention部分可以后面看下;
一些工作将图神经网络(GCNs)[20,39]在图上建立不同节点之间的关系模型,并学习计算机视觉的强大表示。例如,GCN被用于时间性动作定位[50]、视频分类[37,41]、异常检测[51]。基于骨架的动作识别[33,45],点云语义分割[21],图像说明[46]等等。除了GCN,时间关系网络[52],旨在学习和推理视频帧之间的时间依赖关系,被提出来用于解决视频分类。最近,自我注意网络[40,47,5,18]已被成功应用于视觉问题。注意力操作可以通过聚合一组元素的信息来影响单个元素,其中聚合的权重是自动学习的。
实现
总体框架图
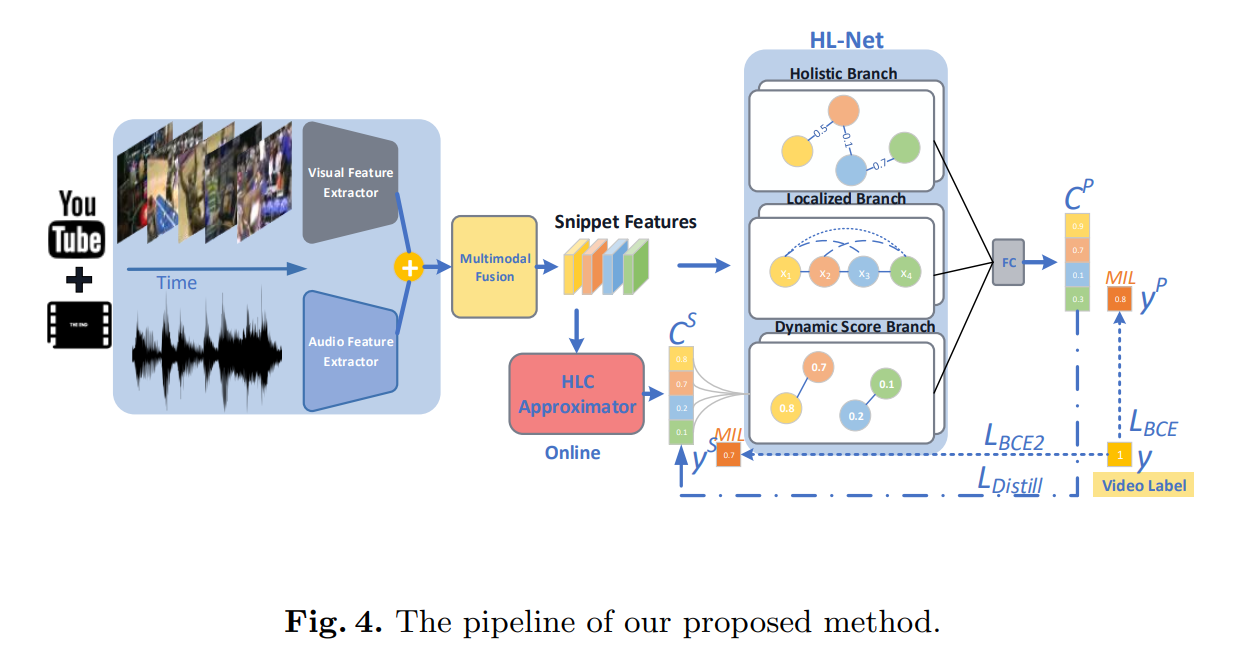
特征提取:using the sliding window mechanism 提取 视频特征和声音特征,合并成融合特征(融合部分不予关注。滑动窗口机制待看)
Visual features: utilize two mainstream networks-C3D and I3D networks. we extract fc6 features from C3D that is pretrained on the Sports-1M dataset, and extract global_pool features from I3D pre-trained on Kinetics-200 dataset.
Holistic and Localized Networks
Holistic - 特征相似性
通用的图卷积表示可以看为:
- GCN范式:
注:$X^H_0 = X^S_0 = X^L_0 = X^F$
特征相似性的邻接矩阵表示:
$A^H_{ij}$衡量第i个和第j个特征的特征相似性;g是归一化函数,f函数计算一对特征的相似性;附录部分还讨论了一下其他版本的。本文定义如下
- f 定义为:
- thresholding操作($\tau$是threshod,f将相似性限制在(0,1]之间):
使用softmax作为归一化函数g,使得A的每一行的和都为1。
localized branch -proximity prior (和时间一致性类似)
Online detection & score branch
正如我们提到的,暴力检测系统不仅适用于离线检测(互联网录像机),也适用于在线检测(监控系统)。然而,上述HL-Net的在线检测受到了一个主要障碍的阻碍:HL-Net需要整个视频来获得长距离的依赖关系。为了跳出这个困境,我们提出了一个HLC近似器,只把以前的视频片段作为输入,在HL-Net的指导下产生精确的预测。两个堆叠的FC层和ReLU以及一个一维因果卷积层构成了HLC近似器。一维因果卷积层的核大小为5,跨度为1,在时间上滑动卷积滤波器。一维因果卷积层也充当分类器,其输出是形状为 T’ 的暴力激活表示为$C^S$。更妙的是,这个操作引入了一个额外的分支,名为动态得分分支(dynamic score branch),以扩展HL-Net,它取决于$C^S$。
score branch
用于online detection, 解决需要将整个视频作为输入(以获得长距离依赖)的问题。
该分支的主要作用是将一个位置的响应计算为所有位置特征的加权和,其中权重取决于分数的接近程度。与整体和局部分支的关系矩阵不同,分数分支的关系矩阵在每次迭代中都会更新,并且取决于预测的分数而不是先验。从形式上看,分数分支的关系矩阵设计如下:
s是 sigmoid, 函数ρ用于加强(和削弱)得分接近度大于(和小于)0.5的配对关系,softmax也用于归一化。
training based on MIL
所有输出($C^P 和 C^S$)在时间维度上的K-max取平均作为输出,以得到$y^P$ 和$y^S$。K定义为T‘ 除以q加一后向下取整。
补充: top-k策略(Weakly-supervised video anomaly detection with robust temporal feature magnitude learning)
- loss结合三个branch
The instances corresponding to the K-max activation in the positive bag is most likely to be true positive instances (violence). The instances corresponding to the K-max activation in the negative bag is hard instances. We expect these two types of instances to be as far as possible.
L_BCE(binary crossentropy) 和L_BCE2分别对应为$y^p 和 y^s$ 与 ground truth y之间的loss。L_DISTILL为知识蒸馏损失。
Inference
方法支持线上和离线的检测。sigmoid函数作为$C^P$和$C^S$的激活函数,并最后生成在[0,1]之间的暴力置信得分。注:在线上预测中,只有HLC近似器工作,HL-NET可以移除。
实验
评估标准
we utilize the frame-level precision-recall curve (PRC) and corresponding area under the curve (average precision, AP) [30] rather than receiver operating characteristic curve (ROC) and corresponding area under the curve (AUC) [44,43]
since AUC usually shows an optimistic result when dealing with class-imbalanced data, and PRC and AP focus on positive samples (violence)
- Precision and Recall (PR曲线):用于稀有事件检测,如目标检测、信息检索、推荐系统。负样本很多的时候,??? = FP⁄(FP+TN)很小,比较TPR和FPR没有太大意义(ROC)
性能表现
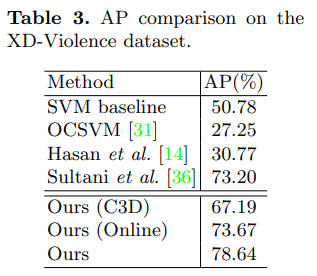
优于当前最先进的方法(20年的文章)
我们观察到,在我们的暴力检测任务中,C3D比I3D差了很大一截。
消融实验
- 五种模态AP对比
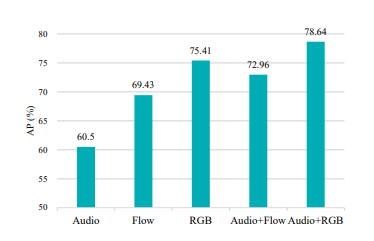
(该文证明声音和视觉的融合检测效果更好,且视觉模态的作用优于声音)
三个分支的对比(holistic, localized and score branches)
- 三个分支单独的情况表现相似
- 移除任何一个分支都会使得表现变差
- HL-NET在这三个分支一起作用的时候表现最好,因此证明三个分支都不可替代。
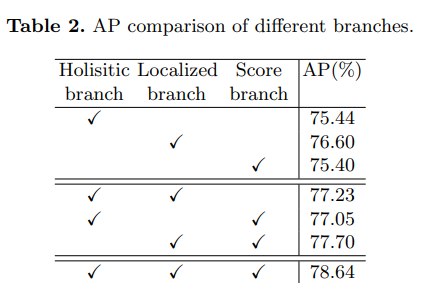
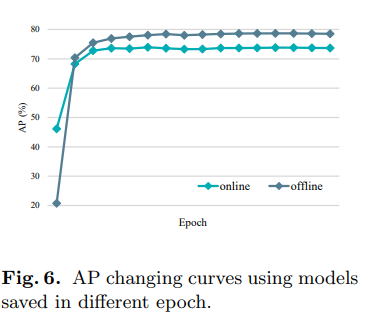
online vs offline
其他
光流
光流(optical flow)是空间运动物体在观察成像平面上的像素运动的瞬时速度。
光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
通常将二维图像平面特定坐标点上的灰度瞬时变化率定义为光流矢量。
作者在《On the Integration of Optical Flow and Action Recognition》这篇文章[1]中深入讨论了光流与行为识别的结合,并通过实验观察到如下结论:
(1)光流对于行为识别是有用的,因为它的外观不变性;
(2)光流法采用最小化端点误差(EPE,end-point-error)来优化,但是当前EPE方法与动作识别性能没有很好的相关性;
(3)对于测试过的光流方法,在边界上和小位移上的精度与动作识别性能最相关;
(4)采用最小化分类误差(而非EPE)来训练光流可以提高识别性能;
(5)用于行为识别任务的光流不同于传统的光流,特别是在人体内部和身体边界处。
原文链接:https://blog.csdn.net/zhang_can/article/details/80259946