CLIP-TSA:CLIP-Assisted Temporal Self-Attention
paper (ICIP 2023)
Abstract
解决VAD问题:由于劳动密集型性质(帧级别的标注?),通常以弱监督的方式表述为多实例学习问题(MIL)。
- 相比该领域传统使用的C3D和I3D模型,我们使用ViT-encoded visual features from CLIP,以使用一种创新的方式来有效地提取判别表示。
- model long- and short-range temporal dependencies, 并使用时间自注意力机制(TSA)来提取重要的片段(snipppets of interest)
- 进行了消融实验,实验表明我们提出的CLIP-TSA 在广泛使用的两个benchmark数据集(UCF-Crime和ShanghaiTech)大范围的优于SOTA
Introduction
分别介绍了有监督、无监督和弱监督(基于MIL框架)的VAD方法的优缺点。
Motivation
弱监督方法的已有提取视频特征骨架C3D、I3D和2Stream的缺陷(它们是在动作识别任务上预训练的):
与动作识别问题不同,VAD依赖于清晰地表示场景中的事件的区别性表征。因此,由于领域的鸿沟(domain gap),这些骨架并不合适[1])。
已有的MIL-based弱监督VAD受限于应对 异常视频中包含任意数量的异常片段
方案
针对性提出解决方案:使用CLIP进行特征提取。
CLIP的优势及其为什么能够有效:
最近(21-23)”vision language”工作的成功证明了通过CLIP(Contrastive Language-Image Pre-traning)框架学习到的特征表示的有效性。
CLIP由两个网络组成:vision encoder 和 text encoder , 在互联网公开可用资源收集到的400 million text-image pairs上训练。给定一组words和一张图片,CLIP可以评估他们之间的语义相似性。
因此,我们使用CLIP作为特征提取器。
提出top-k function
受differentiable top-k operator[2]的启发,提出top-k function, 它定位了视频中感兴趣的κ个片段,并在相似的MIL 设置中采用 differentiable hard attention,以证明其对传统的、流行的设置的有效性和适用性。
引入Temporal Self-attention机制(TSA)
目标是通过衡量片段的异常程度生成重新赋权的注意力特征(reweighted attention feature)
提出的CLIP-TSA采用MIL框架,由三个组件构成:
(1) 使用CLIP进行的特征编码
(2)使用TSA机制在时间维度上进行片段一致性建模
(3) 使用差异最大化训练器定位异常片段
三个评估数据集:UCF-Crime, ShanghaiTech和XD-Violence
Contribution
- 提出适用于弱监督VAD问题的Temporal Self-Attention(TSA)机制,并获得了视频片段的异常似然性得分。
- 我们运用CLIP,它使用ViT作为视觉特征的主干,引入了1)CLIP特征的新用法,2)分析由异常动作组成的视频中的新型上下文表示
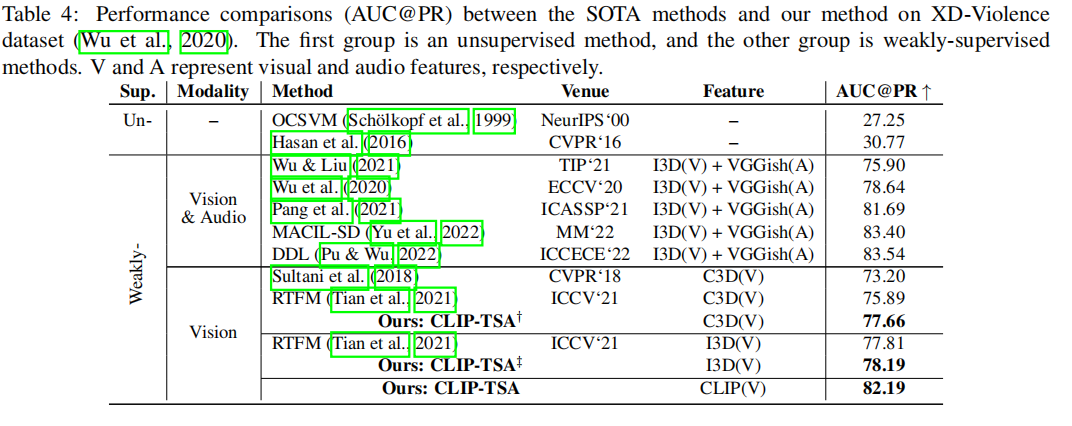
- 经验性地验证了我们提出方法的有效性,结果表明:据我们所知,在任何类型的监督设置下,它实现了比目前所有以UCF-Crime和ShanghaiTech数据集为基准的SOTA方法更优的性能。对于XD-violence数据集,他打败了不融合声音特征进行训练的SOTA
Related Work
- Unsupervised VAD
- Weakly-supervised VAD
- Vision-Language Pre-trained Models
- Attention Mechanism
Method
pipeline如下:
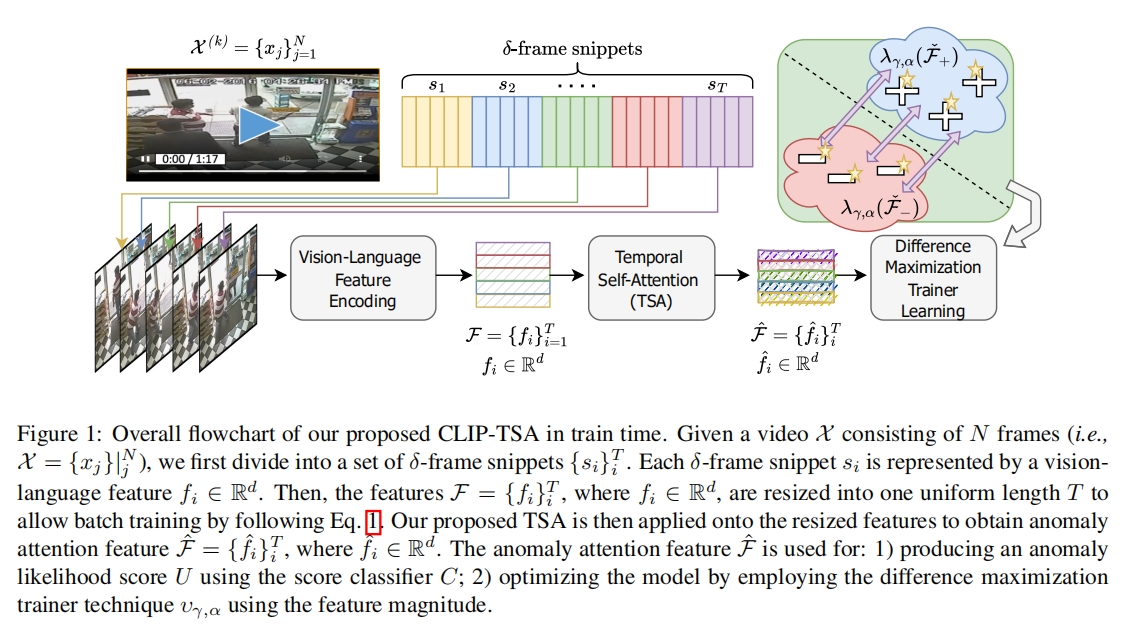
(1) 使用CLIP进行的特征编码
(2)使用TSA机制在时间维度上进行片段一致性建模,并下选取关联最多的top-k个
(3) 使用差异最大化训练器定位异常片段
feature embedding
choose the middle frame $I_i$ that represents each snippet $s_i$
encode frame $I_i$ with the pretrained Vision Transformer to extract visual feature $I_i^f$
then project feature $I_i^f$ onto the visual projection matrix L, which was pretrained by CLIP to obtain the image embedding $f_i = L*I_i^f$
thus got the embedding feature $F_k$ of video X, which consist of snippets
finally apply the video normalization
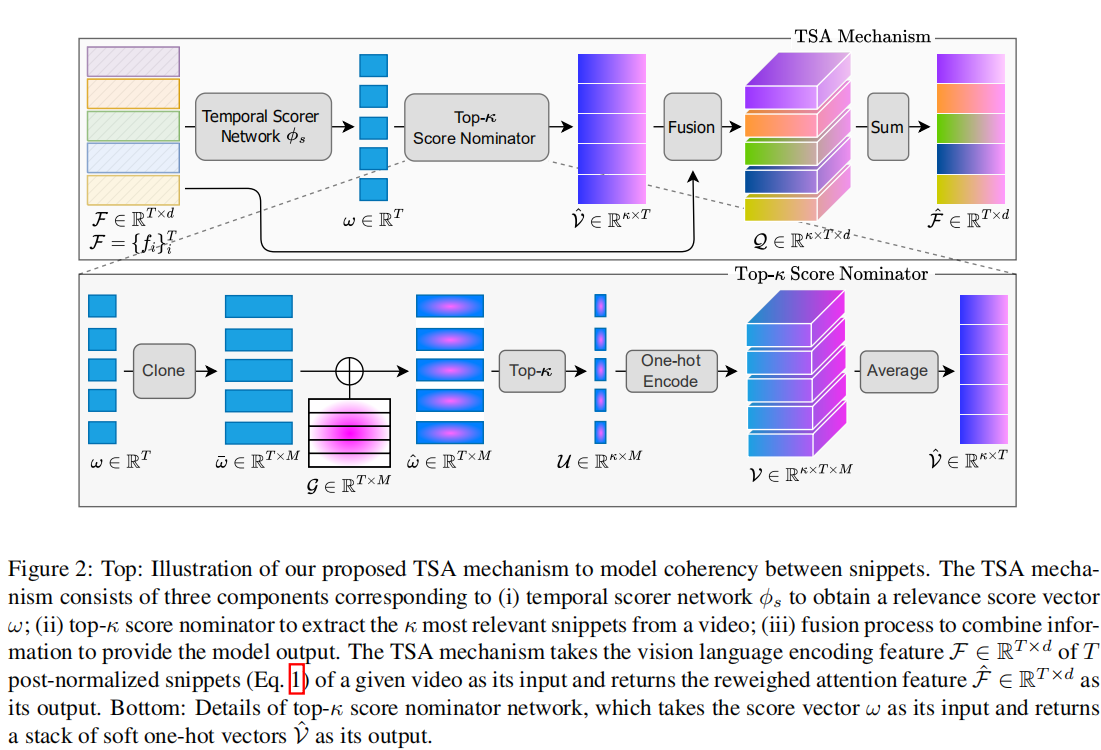
Temporal Self-Attention (TSA)
目标:model the coherency between snippets of a video and select the top-k most relevant snippets
组成: (i) temporal scorer network: 获取score向量。将feature变成score向量($R^{T\times 1}$) ,论文里网络为三层MLP
(ii) top-κ score nominator:提取K个关联性最大的片段。具体见如下算法二。有借助高斯噪声、基于分数幅度获取top-k个、one-hot编码(Through the soft one-hot encoding mechanism, the higher amount of attention, or weight, is placed near and at the indices of top-κ scores)
(iii) fusion network: combine information
输入:前述基于CLIP提取到的特征
输出:reweighted attention Feature

Difference Maximization Trainer Learning
mini batch训练,输入分成2*B(batchsize),一半从normal bags中加载,一半从abnormal bags中加载。
在TSA阶段之后,分别得到两部分的reweighted attention feature。
接着,将feature送入一个卷积网络模块J,J由dilated convolutions和non-local block组成,以此基于重新加权的大小模拟片段之间的长期和短期关系。
输出的convoluted attention features接着送入一个浅层的MIL-based score classifier,输出的分数决定特征片段的二元异常状态。
每个convoluted attention features执行 Difference Maximization Trainer (DMT)
基于特征幅度选取top-a个特征,定义loss将异常片段明显区分于正常片段,具体过程与RTFM论文的类似。
Infer
测试阶段不执行normlization。
分类器最后得到的一组分数U,每个分数$u_i$表示对应index的异常相似度,值为0-1之间。$u_i$被四舍五入取得二元分数,1代表异常,0代表正常。
能够进行帧级别的测试:片段的score(对应片段级结果)保留原始顺序,repeat $\delta$次。
Experimental Results
数据集:UCF-Crime Dataset、ShanghaiTech Campus Dataset、XD-Violence Dataset
指标:AUC@ROC(UCF-Crime、ShanghaiTech)、AUC@PR(XD-Violence)
Performance Comparison
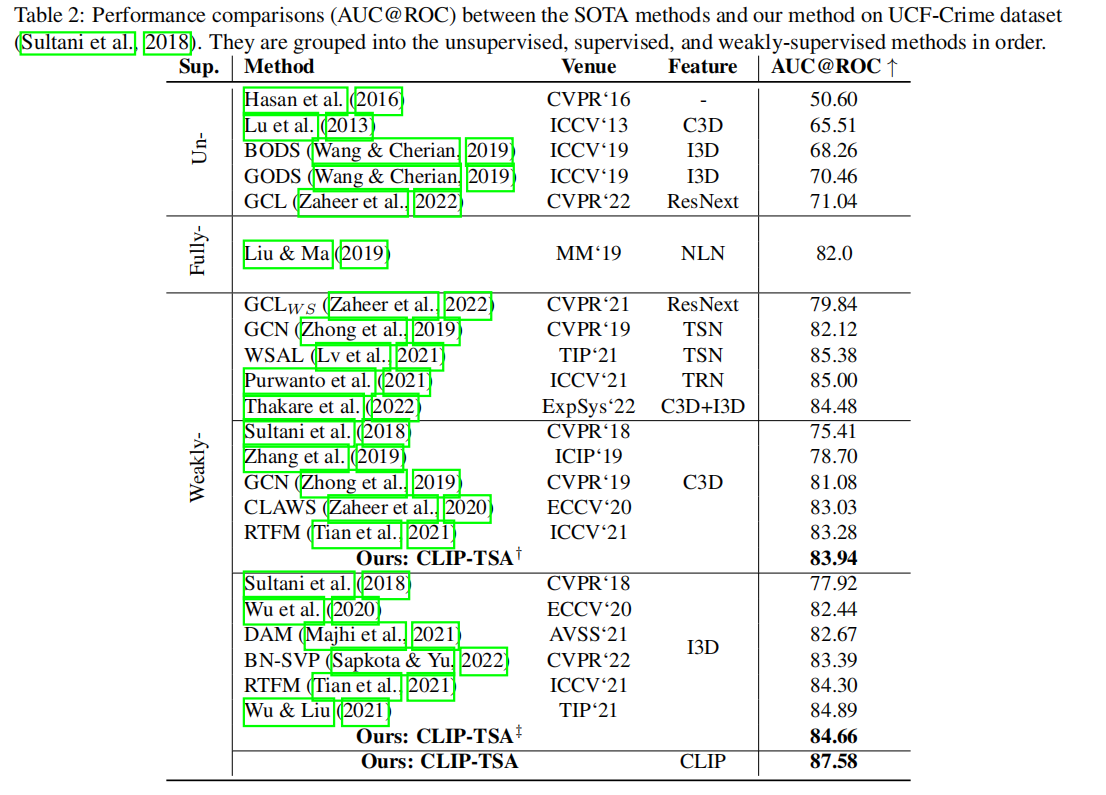
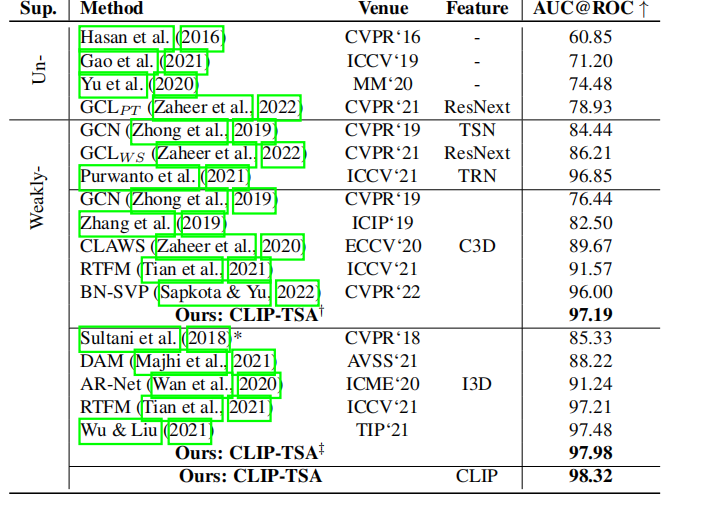
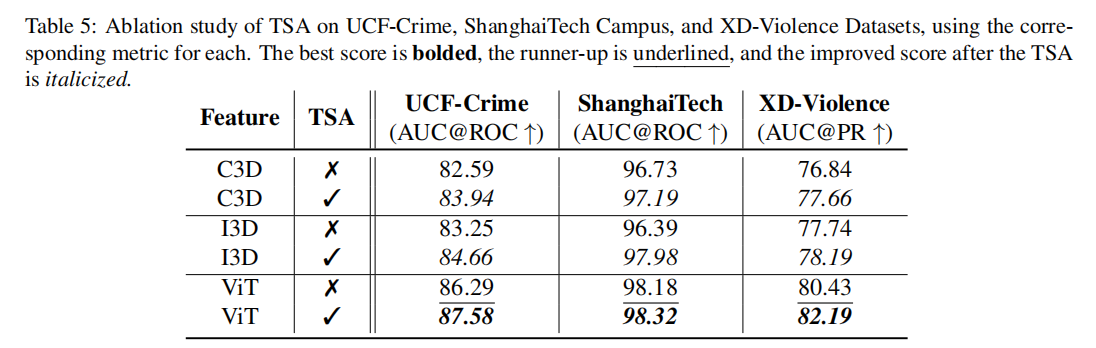
Ablation Study
- TSA机制的有效性:
- K的参数选择
其中,分析的是超参r
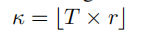
| UCF-Crime | ShanghaiTec | XD-violence |
|---|---|---|
| 0.7 | [0.3,0.7] | 0.9 |
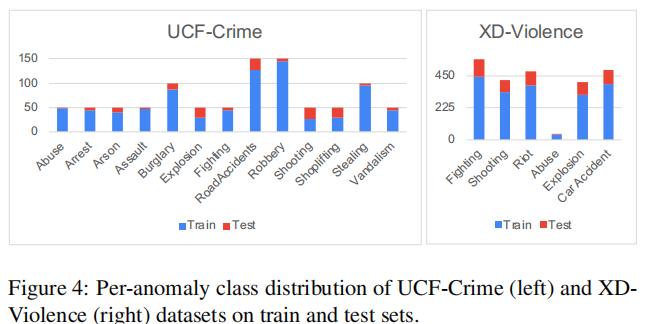
作者通过分析数据分布,来解释最优r值在不同数据集之间不同的原因:
信息:1)data distribution of UCF-Crime (1,900 videos with 13 types of anomalies), ShanghaiTech Campus (317,398 videos with 130 anomaly events), and XD-Violence (4,754 videos with 6 types of anomalies) datasets
2)frame-level anomaly-to-all ratio of their test sets, which are 0.1819, 0.4247, and 0.4977,
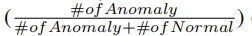
基于信息给到的分析:
ShanghaiTec是一个具有较多异常事件的大尺度数据,因此我们假设该模型具有足够的泛化性,因此,值设为[0.3,0.7]在anomaly-to-all ratio 附近。
而UCF-Crime和XD-Violence具有不平衡的类分布。此外,做良好判别的决策所依赖的重要特征,不仅限于异常片段,也包括了一些正常片段,特别是作为损失计算的一部分,其中异常top片段和正常片段的幅度都被考虑在内。因此,这两个数据集的最好r不分布在anomaly-to-all ratio附近。
Conclusion
本文提出了一种有效的端到端弱监督VAD框架CLIP-TSA。具体地说,我们提出了一种新的TSA机制,它可以在最小限度的情况下最大化对特征子集的注意力关注噪声,并显示了其对弱监督VAD问题的适用性。我们还将TSA应用于clip提取的特征,以证明其对视觉语言特征的有效性,并在弱监督的VAD问题中利用视觉语言特征。通过将我们的数据集与sota进行比较,我们还通过经验验证了我们的模型在VAD的三个流行数据集上的卓越性。
未来的研究可能着眼于更好的技术,以结合时间和空间信息,并以较少的注释处理不平衡的数据。
像 Li 等人 (2022)[3]这样的注意力技术 和自监督学习 (Caron 等人, 2021; Chen 等人, 2020a) 也是提高性能的潜在扩展。
引用:
[1] Kun Liu and Huadong Ma. Exploring background-bias for anomaly detection in surveillance videos. In Proceedings of the 27th ACM International Conference on Multimedia, pp. 1490–1499, 2019.
[2] Jean-Baptiste Cordonnier, Aravindh Mahendran, Alexey Dosovitskiy, Dirk Weissenborn, Jakob Uszkoreit, and Thomas Unterthiner. Differentiable patch selection for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2351–2360, June 2021.
[3] Yehao Li, Ting Yao, Yingwei Pan, and Tao Mei. Contextual transformer networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.