使用wandb可视化参数选取
Sweep
在高维超参数空间中搜索,以找到性能最好的模型,会很不方便。超参数sweep提供了一种有组织的、有效的方法来进行模型的大决战,并挑选出最准确的模型。它们通过自动搜索超参数值的组合(如学习率、批量大小、隐藏层数量、优化器类型)来找到最优化的值。
官方教程colab:
Organizing_Hyperparameter_Sweeps_in_PyTorch_with_W&B.ipynb - Colaboratory (google.com)
Tutorial
setup
可参见前一篇文章。
1 | pip install wandb -Uq |
1 | wandb.login() |
现在开始正式的来使用sweep!
注:后续代码都是python代码,1-3都在main.py中写即可。
1. Define the sweep
1.1 选择搜索方法
We provide the following search
methods:
gridSearch – Iterate over every combination of hyperparameter values. Very effective, but can be computationally costly.
randomSearch – Select each new combination at random according to provideddistributions. Surprisingly effective!
bayesian Search – Create a probabilistic model of metric score as a function of the hyperparameters, and choose parameters with high probability of improving the metric. Works well for small numbers of continuous parameters but scales poorly.
1 | sweep_config = { |
设置目标:
1 | metric = { |
如果是acc,那么就是maximize
1.2 命名超参数
1 | parameters_dict = { |
不想变化的超参数, 值设一个:
1 | parameters_dict.update({ |
可以给出分布:设置分布
1 | parameters_dict.update({ |
看看现在的sweep_config:
1 | import pprint |
1 | {'method': 'random', |
- 早停及其他设置等:
https://docs.wandb.com/sweeps/configuration#stopping-criteria
2. initialize the Sweep
1 | sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo") |
3. run the Sweep agent
1 | import torch |
1 | def build_dataset(batch_size): |
1 | wandb.agent(sweep_id, train, count=5) |
可视化结果
去url查看即可
Parallel Coordinates Plot
将超参数值映射到模型度量。
面板左侧可以选择对某些run进行隐藏,隐藏之后,【并行关联plot】和后面说到的【参数重要性plot】中都会隐藏和排除那些run。
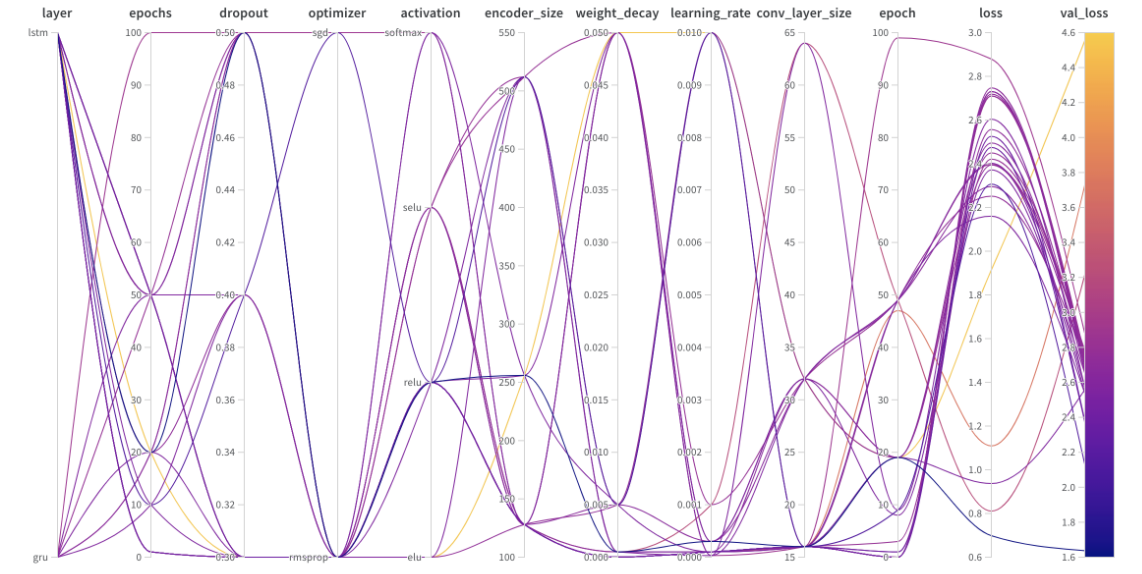
超参数重要性
Hyperparameter Importance Plot
超参数的重要性图浮现了哪些超参数是你的指标的最佳预测因素。报告特征重要性(来自随机森林模型)和相关性(隐含线性模型)。
Parameter Importance | Weights & Biases Documentation (wandb.ai)
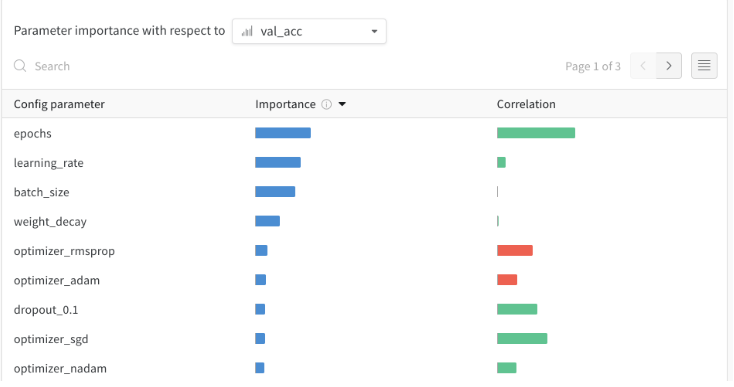
重要性列
显示了每个高参数在预测所选度量方面有用的程度。我们可以想象一种场景,首先要调整大量的超参数,并利用这种情节来磨练哪些值得进一步的探索。然后,随后的扫描可能仅限于最重要的超参数,从而更快,更便宜。
注意:我们使用基于树的模型而不是线性模型来计算这些重要性,因为前者对分类数据和不归一化的数据更有宽容度。
在下一步中,我们可能会再次扫荡探索这些超参数的更多细粒度值。有趣的是,尽管Learning_rate和batch_size很重要,但它们与输出的相关性并不很好。这就引入到我们说的【相关性】。
相关性
捕获单个超参数和度量值之间的线性关系。他们回答了这个问题 : 使用超参数(例如SGD Optimizer)和我的Val_loss(在这种情况下的答案是肯定的)之间是否存在显着关系。相关值范围为-1到1,其中正值代表正线性相关,负值代表负线性相关,值为0表示无相关。通常,在任一方向上大于0.7的值表示强相关。
我们可能会使用此图来进一步探索与我们的度量相关性较高相关的值(在这种情况下,我们可能会选择随机梯度下降,或者在RMSPROP或NADAM上选择ADAM)或训练更多时代。
关于解释相关性需要注意的地方:
相关性显示了关联的证据,不一定是因果关系。
相关性对离群值敏感,离群值可能会将牢固的关系转化为中等的关系,特别是如果尝试的超参数的样本量很小,则可能会将其变为中间的异常值。
最后,相关仅捕获超参数和指标之间的线性关系。如果存在牢固的多项式关系,则不会被相关性捕获。
重要性与相关性之间的差异是由于重要性解释了超参数之间的相互作用,而相关性仅测量单个超参数对度量值的影响。其次,相关仅捕获线性关系,而重要性可以捕获更复杂的关系。
如您所见,重要性和相关性是了解超参数如何影响模型性能的强大工具。
进阶
- config可选项,包括early stop ,scheduler等
bayesian Search
bug记录
运行有时候还是会出现process communicating error,解决方案参见前一篇文章。具体修改
with wandb.init():自己的错误:由于自己训练模型的时候有
import train from train(自定义的方法),而此次使用sweep又def 了一个train(),与train同名,产生错误。network error
即使我fork了之后,sweep过程中,总是有几次会network error,随后报错process communicating failed。虽然其会继续下一次的实验,但是这样很影响。
wandb: Network error (ConnectionError), entering retry loop._harry_tea的博客-CSDN博客
解决方式1:offline 部署
offline部署
- 在文件开头加上
1 | os.environ["WANDB_API_KEY"] = YOUR_KEY_HERE |
最后训练完后会出现
wandb sync wandb/xxx,按照提示同步即可shell命令执行
wandb sync | Weights & Biases Documentation
我offline跑sweep,然后把所有的run wandb sync,发现错误。sweep不正常
metric未和log里的名称对应,注意,对应的是name之间的对应,而不是value的变量名!
offline的情况下出现其他问题(sync之后只能找到4/10个run)
此外,在offline sync过程中,有时候会出现network error,过一会就能走了(retry loop)
online 记录
- online跑,wandb.init()
reinit=True这一参数没有设置,并且设置setting=wandb.Settings(start_method=("thread")),成功运行中