视频生成实践
视频生成实践
依照开源代码部署模型,实现文生视频/图生视频。以下仓库为记录存储几种视频生成方法:
https://github.com/Xandra298/VideoGen
其中,I2VGen-XL和text-to-video-synthesis论文大体介绍如下。
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Comment: Project page: https://i2vgen-xl.github.io
Abstract
challenge
- 缺乏对齐良好的文本-视频数据
- 视频复杂的固有结构,使得模型难以同时确保语义和定性的卓越性。
解决方案
在本报告中,我们提出了一种级联 I2VGen-XL 方法,该方法通过解耦这两个因素来增强模型性能,并通过利用静态图像作为关键指导形式来确保输入数据的对齐。
两个步骤:
- base stage: 通过使用两个分层编码器来保证连贯的语义并保留输入图像中的内容
- refinement stage: 通过加入额外的简短文本来增强视频的细节,并将分辨率提高到 1280×720。
效果:通过这种方式,I2VGen-XL可以同时提高语义的准确性、细节的连续性和生成视频的清晰度。贡献:
- 收集约3500万个单镜头文本视频对和60亿个文本-图像对来优化模型。
- 通过大量的实验,我们研究了I2VGenXL的基本原理,并将其与当前的顶级方法进行了比较,这可以证明其在各种数据上的有效性
Method
Preliminary
- LDM
潜在扩散模型(LDM)是一种有效且高效的扩散模型,它从高斯噪声中逐渐恢复目标潜伏,保留视觉流形,并最终从潜伏中重建高保真图像或视频。
在本报告中,除非另有说明,否则我们将使用 3D 架构的 LDM 称为 VLDM。
该论文使用的VLDM主要是VideoComposer[1]。
[1] Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. NeurIPS, 2023. 2, 3, 4
I2VGen-XL

它需要实现两个关键目标:
- 语义一致性,包括准确预测图像的意图,然后在保持输入图像的内容和结构的同时生成精确的动作;
- 高度的时空连贯性和清晰度,这是视频的基本属性,对于确保视频创作应用程序的潜力至关重要。
1. base stage
在低分辨率: 448*256
主要侧重于基于输入图像整合多级特征提取,包括高级语义和低级细节学习, 确保意图理解并有效保存内容。
High-level semantics learning
- 仅使用visual encoder of CLIP导致生成的视频中输入图像的内容和结构保存不佳:主要原因是因为CLIP的训练目标是进行视觉文本特征的对齐以学习高阶语义,但是会忽略对图像中精细细节的感知。
- 论文合并一个额外的可训练全局编码器(即 G.Enc.),学习具有相同形状的互补特征,来缓解上述问题。
- 然后,通过加法运算将两个一维特征集成在一起,并使用交叉注意力嵌入到3D UNet的每个空间层中。
尽管做出了这些努力,但将输入图像压缩为低维向量仍然会导致信息丢失。
Low-level details
为了减少细节的损失,我们采用了从VQGAN编码器(即D.Enc.)中提取的特征,并将它们直接添加到第一帧的输入噪声中。(这种选择是基于编码器完全重建原始图像的能力而做出的,确保保留其所有细节。)
我们的实验表明,使用本地编码器而不是更复杂的语义编码器可以使视频更好地保留图像内容。
然而,随着视频的播放,出现了明显的失真,表明语义的清晰度正在下降。这突出了两个分层编码器的互补性,表明它们的集成是有利的。
2. Refinement stage
通过1.,我们可以获得具有多种多样且语义准确的动作的低分辨率视频。
但是,这些视频可能会受到各种问题的影响,例如噪声、时间和空间抖动以及变形。
Refinement stage的目标:
- 提高视频分辨率,将其从 448 × 256 提高到 1280 × 720 或更高;
- 提高视频的时空连续性和清晰度,解决时间和空间上的伪影。
为了提高视频质量,我们训练了一个单独的VLDM,专门处理高质量、高分辨率的数据,并在第一阶段生成的视频上采用SDEdit 执行noising-denoising process。
与基本模型不同,细化模型使用用户提供的简单文本(例如几个单词)作为条件,而不是原始输入图像。(原因是我们发现,当两个阶段的输入条件相同时,视频校正的有效性会显著降低。这可能是由于引入了具有相同条件的类似映射导致缺失模型中的恢复能力。另一方面,引入不同的条件会带来有效的补偿。)
具体来说,我们使用 CLIP 对文本进行编码,并通过交叉注意力将其嵌入到 3D UNet 中。然后,基于基础阶段的预训练模型,我们使用精心挑选的高质量视频训练高分辨率模型,所有这些视频的分辨率都大于 1280 × 720。
Experiment
Datasets. WebVid10M and LAION-400M, as well as private datasets consisting of video-text pairs and image-text pairs of the same type. 3500万个单镜头文本视频对和60亿个文本-图像对
sota对比
sota方法:Gen2 and Pika
Gen2: Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. arXiv preprint arXiv:2302.03011, 2023
Pika: Pika Lab discord server. https://www.pika. art. 2023
对比类型:pseudo-factual, real, and abstract paintings

结论
i) 运动的丰富性:我们的结果表现出更逼真和多样化的运动,例如飞狗的例子。相比之下,Gen-2 和 Pika 生成的视频似乎更接近静态状态,表明 I2VGen-XL 实现了更好的运动丰富度;
ii) ID保留程度:从这三个样本中可以看出,Gen-2和Pika成功地保留了物体的身份,而我们的方法丢失了输入图像的一些细节。在我们的实验中,我们还发现ID的保留程度和运动的强度表现出一定的权衡关系。我们在这两个因素之间取得平衡。
对Refinement Model 的分析
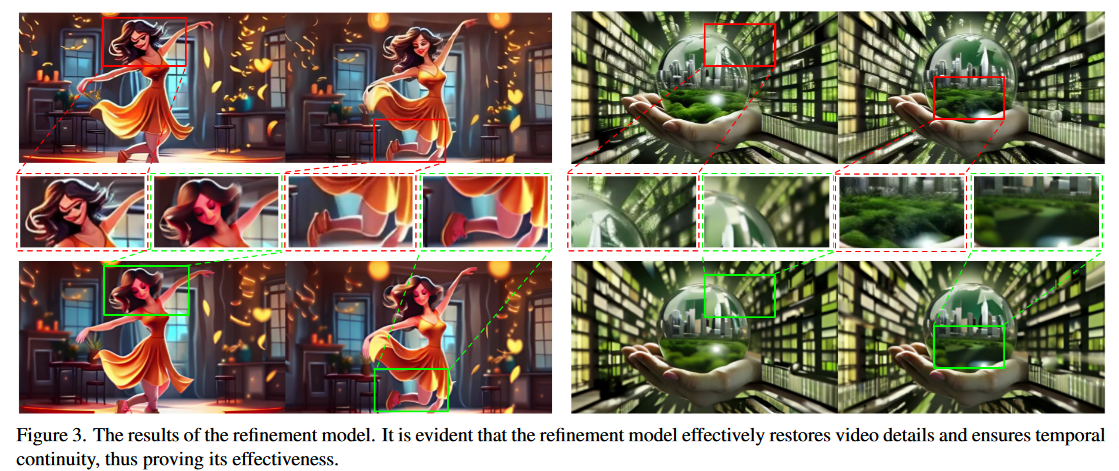
这些结果揭示了空间细节的显著增强,包括精致的面部和身体特征和局部细节中的噪点明显降低。
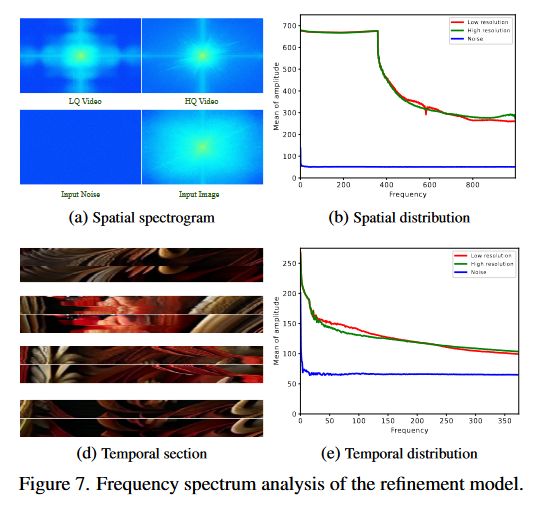
Fig. 7b: 细化模型有效地保留了低频数据,同时在高频数据中表现出更平滑的变化
Fig. 7d 表明高清视频的连续性有了明显的改善。
人类移动效果:

Limitations
i) 人体运动的生成。如前所述,人体运动的生成在自由度和自然性方面仍然存在重大挑战。这主要是由于与人类相关的运动的复杂性和丰富性,这增加了生成的难度;
ii) 生成长视频的能力有限。目前的模型主要以单镜头生成几秒钟的短视频为主,还不能生成连续叙事、多场景的长视频;
iii) 对用户意图的理解有限。目前视频文本配对数据的稀缺性限制了视频合成模型理解用户输入的能力。
ModelScope Text-to-Video Technical Report
Project page: https://modelscope.cn/models/damo/text-to-video-synthesis/summary
Method
ModelScopeT2V
Overview
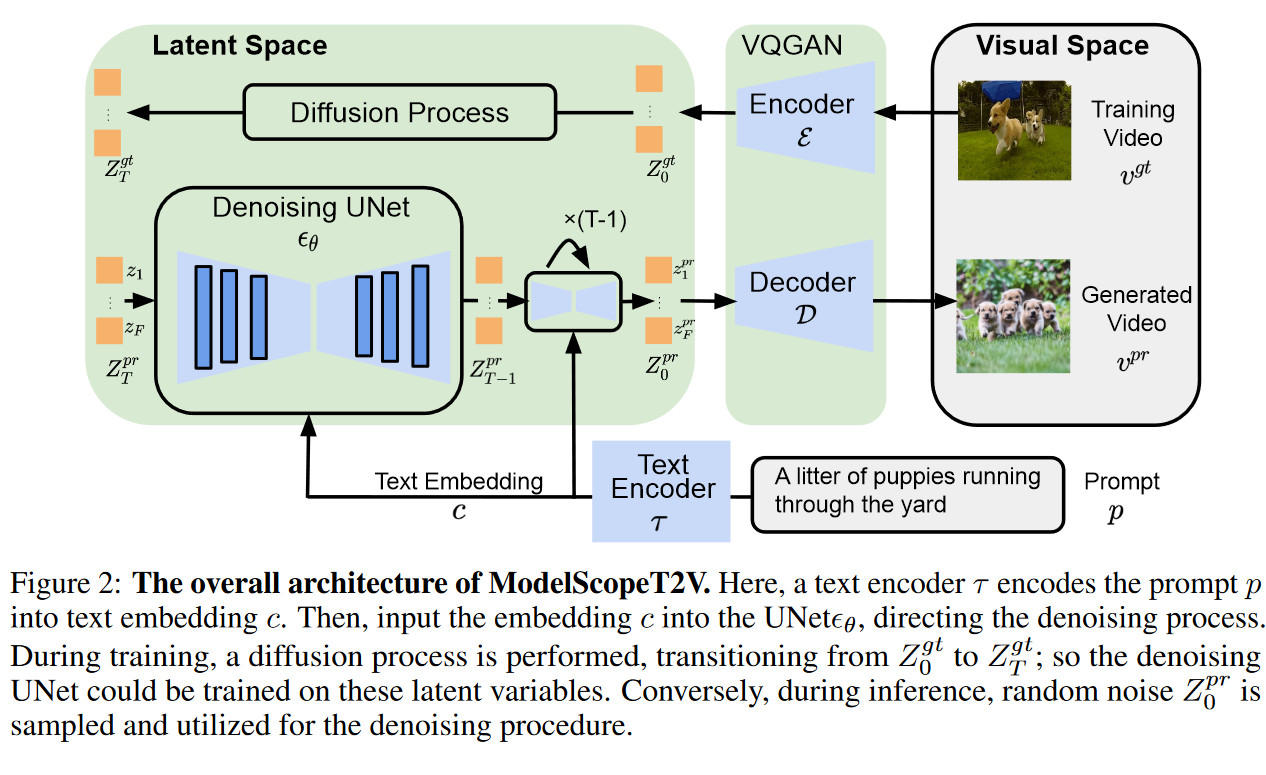
本文中的潜在空间由VQGAN提出。
在训练过程中,扩散过程通过添加高斯噪声$[\epsilon_1^{gt},\ldots,\epsilon_T^{gt}]$ 来将 $Z_0^{gt}$ 变成 $Z_T^{gt}$。因此,我们有$[Z_0^{gt},…,Z_T^{gt}]$ 随着扩散过程的进行,它包含的信息越来越少。在推理过程中,UNet 预测每个步骤的附加噪声,因此我们最终从随机噪声 $Z_T^{gt}$生成 $Z_0^{gt} = [Z_1^{pr},…,Z_F^{pr}]$ 。然后我们可以通过 VQGAN 解码器 $D$ 生成一个视频 $v^{pr}$,如下所示:
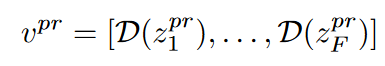
Text conditioning mechanism
受Stable Diffusion 的启发,用交叉注意力机制增强了UNet结构。具体来说,使用Spatio-temporal block中prompt p的文本嵌入c作为多头注意力层中的键和值。这使得中间的 UNet 能够无缝聚合文本特征,从而促进语言和视觉嵌入的对齐。为了确保语言和视觉之间的良好一致性,利用预训练的 CLIP ViT-H/14 中的文本编码器将提示 p 转换为文本嵌入 c。
Denoising UNet
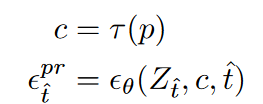
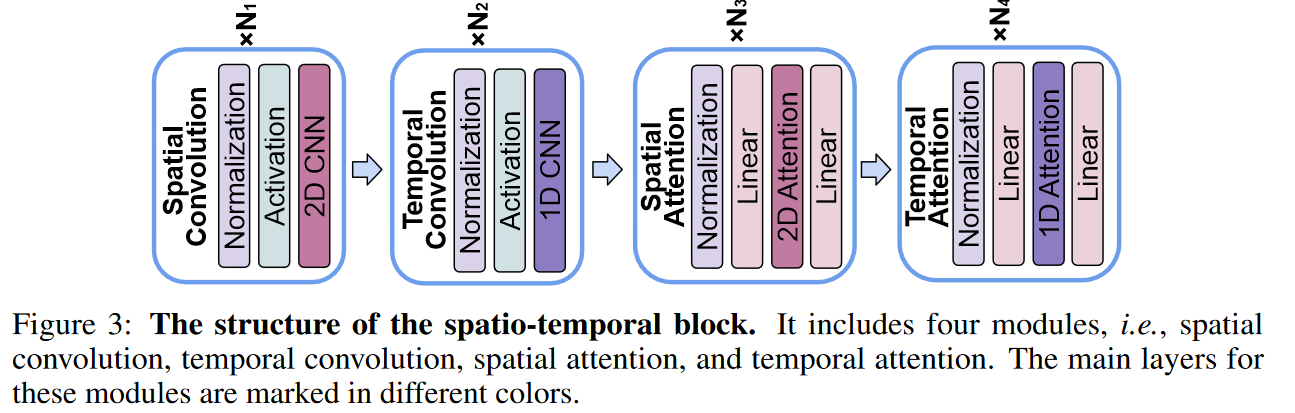
Spatio-temporal block
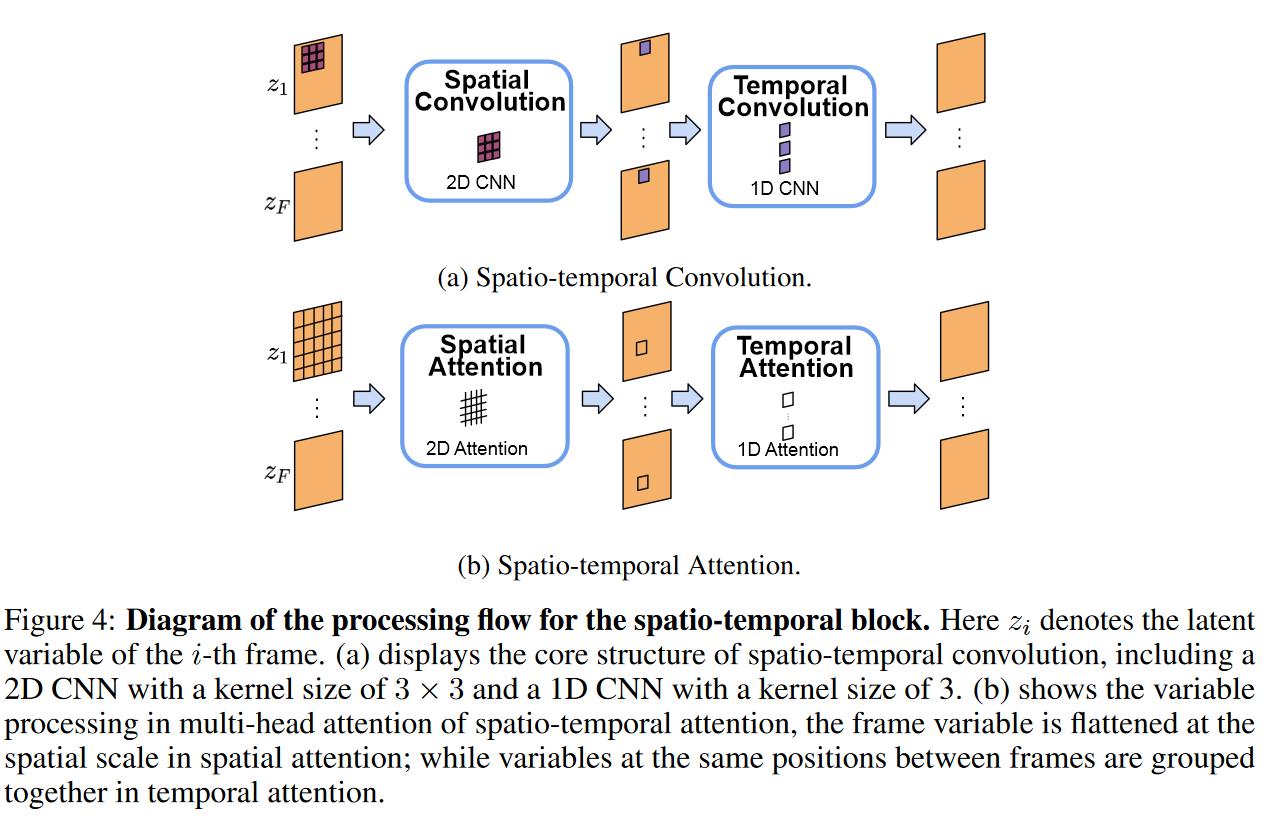
Multi-frame training
ModelScopeT2V 旨在在大规模视频-文本配对数据集上进行训练,例如 WebVid,它与视频生成领域一致。尽管如此,与图像-文本配对数据集(如LAION)相比,此类数据集的规模要小几个数量级。尽管使用Stable Diffusion初始化了ModelScopeT2V的空间部分,但仅对视频文本配对数据集进行训练可能会阻碍语义多样性,并导致在训练过程中灾难性地忘记图像域专业知识。为了克服这一局限性并利用两个数据集的优势,我们提出了一种多帧训练方法。具体来说,八分之一的用于训练的 GPU 应用于图像-文本配对数据集,而其余的 GPU 处理视频-文本配对数据集。由于模型结构可以适应任何帧长度,因此对于在图像-文本配对数据集上进行训练的 GPU,可以将一个图像视为帧长度为 1 的视频。
Experiment
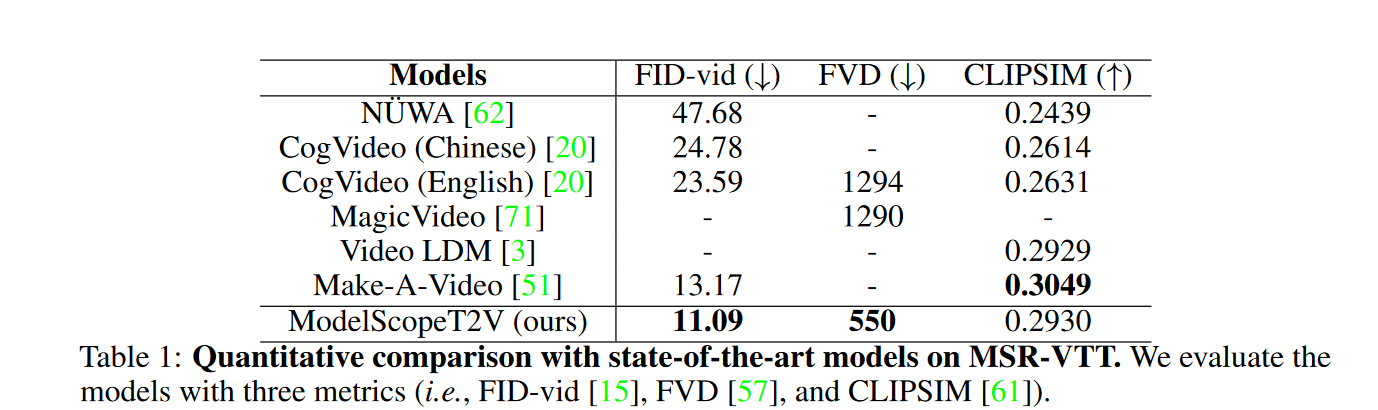
Qualitative results
对比: Make-A-Video 和 Imagen Video
https://imagen.research.google/video

