Retrieval Augmented Generation (RAG)
What is RAG
- Motivation:
- challenges when working with LLMs,such as domain knowledge gaps, factuality issues, and hallucination(幻觉).
- Retrieval Augmented Generation (RAG) 通过引入外部知识源来增强LLMs以缓解上述问题,augmenting LLMs with external knowledge such as databases.
- 一个关键的优势是RAG方法不需要为任务特定的应用重新训练LLM
- RAG can help reduce issues of hallucination or performance when addressing problems in a highly evolving environment.
定义
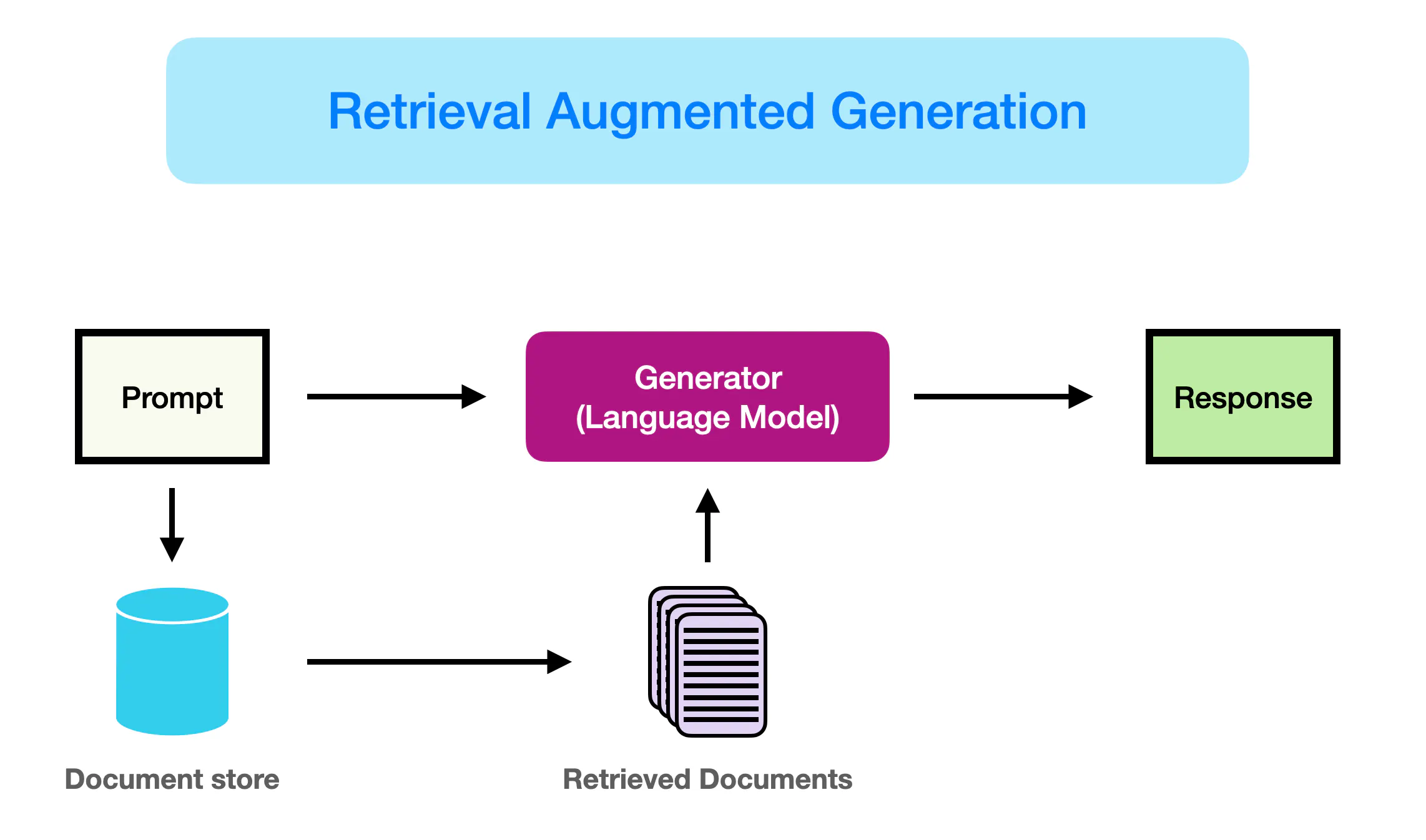
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。来源:Retrieval Augmented Generation (RAG) for LLMs | Prompt Engineering Guide (promptingguide.ai);Retrieval Augmented Generation (RAG) | Prompt Engineering Guide (promptingguide.ai)
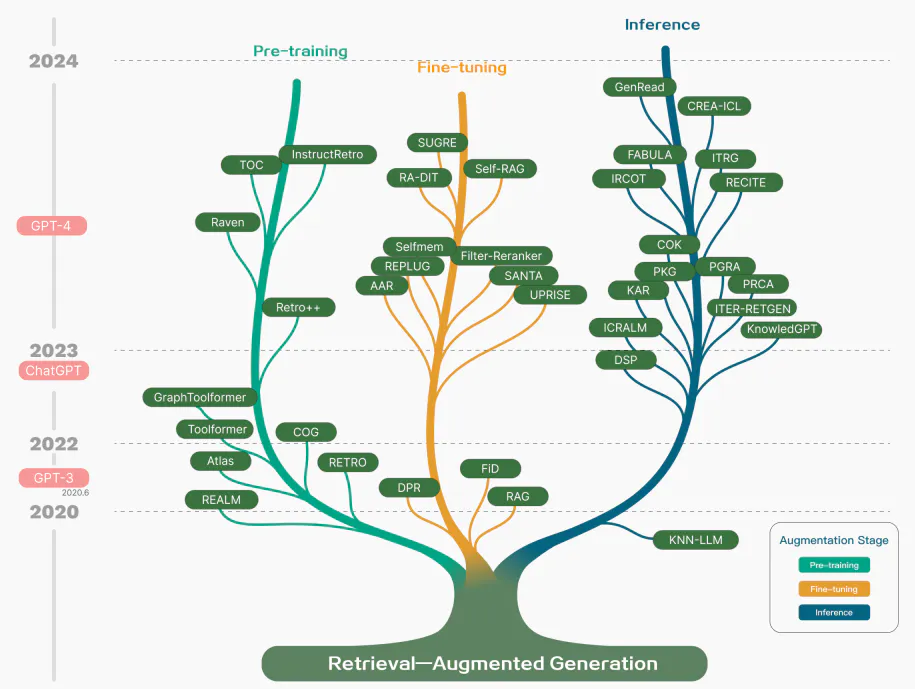
RAG research
While RAG has also involved the optimization of pre-training methods, current approaches have largely shifted to combining the strengths of RAG and powerful fine-tuned models like ChatGPT and Mixtral. The chart below shows the evolution of RAG-related research:
A typical RAG application workflow
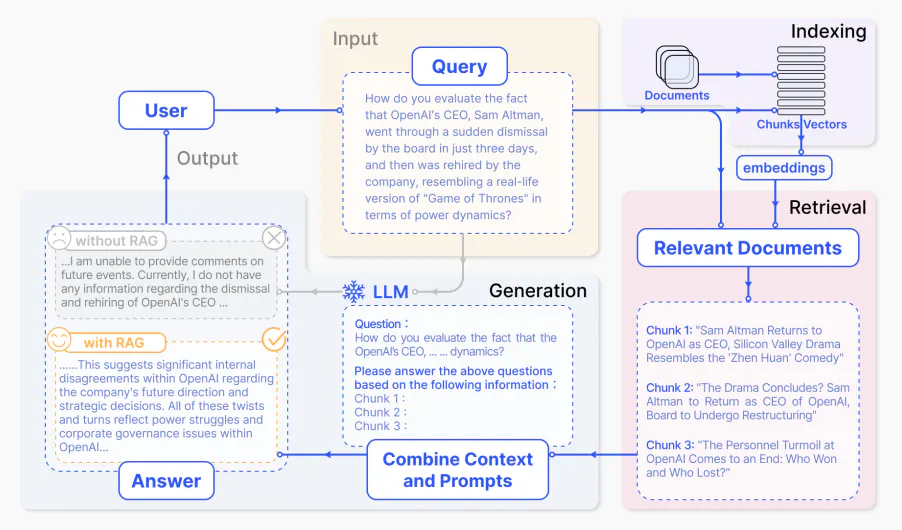
We can explain the different steps/components as follows:
- Input: The question to which the LLM system responds is referred to as the input. If no RAG is used, the LLM is directly used to respond to the question.
- Indexing: If RAG is used, then a series of related documents are indexed by chunking them first, generating embeddings of the chunks, and indexing them into a vector store. At inference, the query is also embedded in a similar way.
- Retrieval: The relevant documents are obtained by comparing the query against the indexed vectors, also denoted as “Relevant Documents”.
- Generation: The relevant documents are combined with the original prompt as additional context. The combined text and prompt are then passed to the model for response generation (refer to the pic: Please answer the above questions based on the following information:…) which is then prepared as the final output of the system to the user.
In the example provided, using the model directly fails to respond to the question due to a lack of knowledge of current events. On the other hand, when using RAG, the system can pull the relevant information needed for the model to answer the question appropriately.
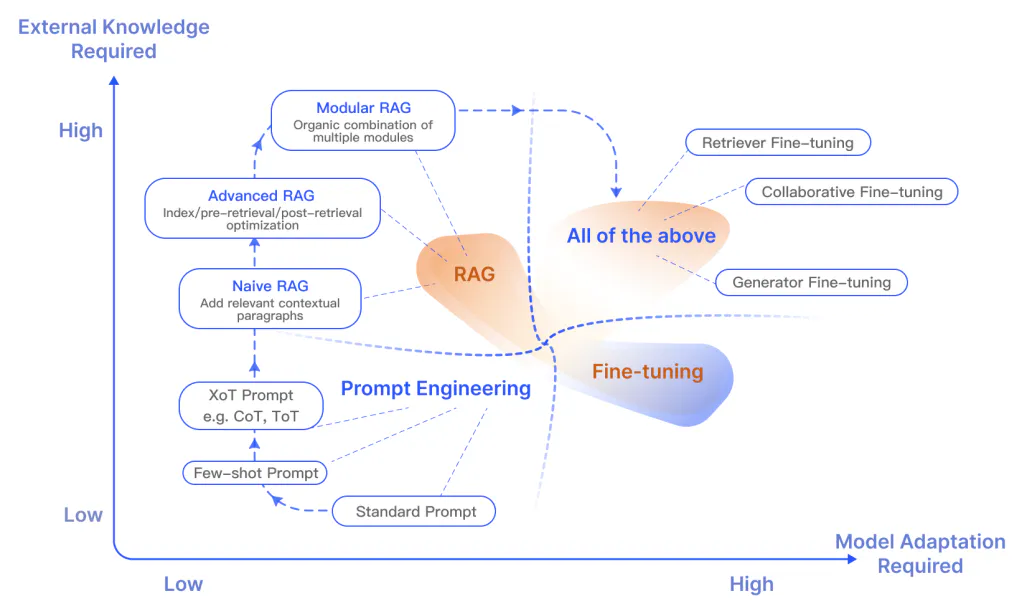
RAG Paradigms
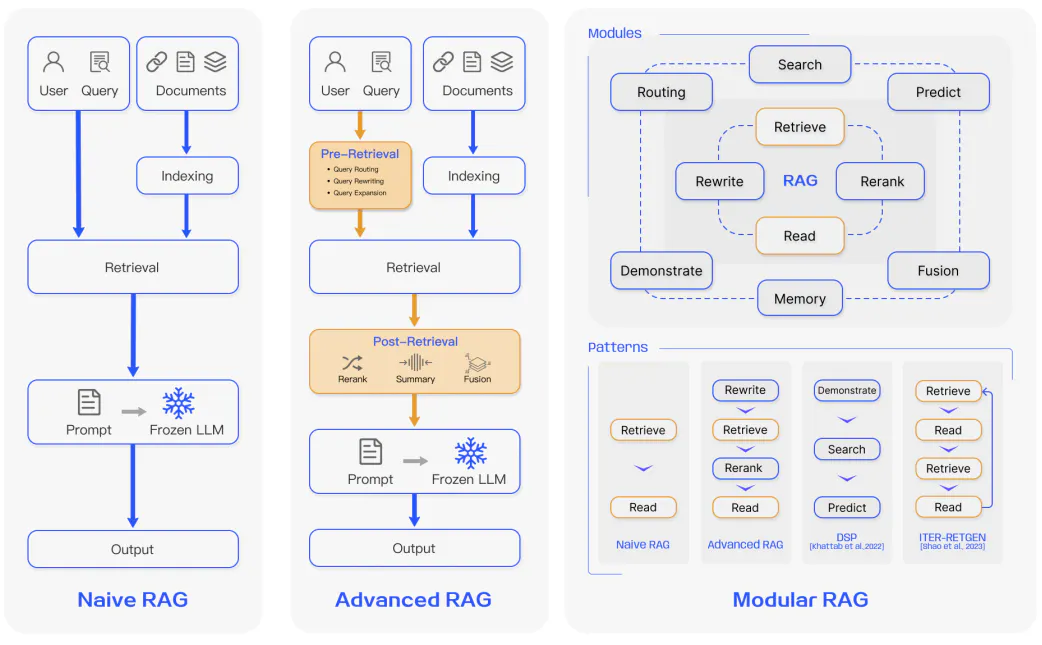
Naive RAG
follows the traditional aforementioned process of indexing, retrieval, and generation
LIMITATIONS
- low precision (misaligned retrieved chunks)
- low recall (failure to retrieve all relevant chunks)
- may pass outdated information
leads to hallucination issues and poor and inaccurate responses.
challenge:
- 冗余和重复问题
- 确保生成任务不会过度依赖增强信息,这可能导致模型只是重复检索到的内容
Advanced RAG
有助于处理 Naive RAG 中存在的问题,例如提高检索质量,这可能涉及优化检索前、检索和检索后过程。
pre-retrieval process
involves optimizing data indexing which aims to enhance the quality of the data being indexed through five stages: enhancing data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval.
retrieval stage
optimizing the embedding model itself which directly impacts the quality of the chunks that make up the context.This can be done by fine-tuning the embedding to optimize retrieval relevance or employing dynamic embeddings that better capture contextual understanding (e.g., OpenAI’s embeddings-ada-02 model).
post-retrieval
avoiding context window limits and dealing with noisy or potentially distracting information. A common approach to address these issues is re-ranking which could involve approaches such as relocation of relevant context to the edges of the prompt or recalculating the semantic similarity between the query and relevant text chunks. Prompt compression may also help in dealing with these issues.
Modular RAG
Modular RAG enhances functional modules. Extended RAG modules include search, memory, fusion, routing, predict, and task adapter which solve different problems. Modular RAG benefits from greater diversity and flexibility.
other important optimization techniques
- Hybrid Search Exploration, such as keyword-based search and semantic search
- Recursive Retrieval and Query Engine
- StepBack-prompt
- Sub-Queries
- Hypothetical Document Embeddings
RAG Framework
The key developments of the components of a RAG system: Retrieval, Generation, and Augmentation.
Retrieval
Retrieval is the component of RAG that deals with retrieving highly relevant context from a retriever.
增强其功能的方式包括:
- Enhancing Semantic Representations. 涉及的考量:
- Chunking: One important step is choosing the right chunking strategy which depends on the content you are dealing with and the application you are generating responses for. Different models also display different strengths on varying block sizes.
- Fine-tuned Embedding Models: Once you have determined an effective chunking strategy, it may be required to fine-tune the embedding model if you are working with a specialized domain.
- Aligning Queries and Documents
- Aligning Queries and LLM
Generation
The generator in a RAG system is responsible for converting retrieved information into a coherent text that will form the final output of the model.
这一过程涉及多种输入数据,有时需要努力完善语言模型,使其适应来自查询和文档的输入数据。
This can be addressed using post-retrieval process and fine-tuning:
Post-retrieval with Frozen LLM
检索后处理不触及 LLM,而是侧重于通过信息压缩和结果重排等操作来提高检索结果的质量。
Fine-tuning LLM for RAG
Argumentation
Augmentation involves the process of effectively integrating context from retrieved passages with the current generation task.
can be applied in many different stages such as pre-training, fine-tuning, and inference.
- Augmentation Stages
- Augmentation Source A RAG model’s effectiveness is heavily impacted by the choice of augmentation data source. Data can be categorized into unstructured, structured, and LLM-generated data.
- Augmentation Process For many problems (e.g., multi-step reasoning), a single retrieval isn’t enough so a few methods have been proposed:
- Iterative retrieval
- Recursive retrieval
- Adaptive retrieval
RAG vs Finetuning
Research in these two areas suggests that RAG is useful for integrating new knowledge while fine-tuning can be used to improve model performance and efficiency through improving internal knowledge, output format, and teaching complex instruction following.
RAG Evaluation
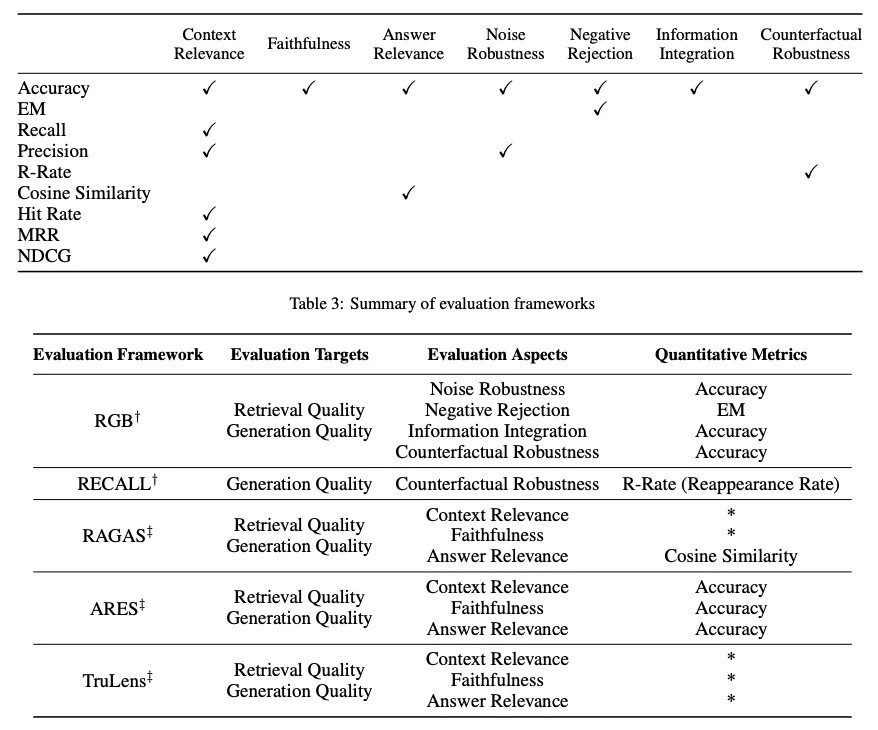
RAG evaluation targets are determined for both retrieval and generation where the goal is to evaluate both the quality of the context retrieved and the quality of the content generated.
- retrieval quality: metrics used in other knowledge-intensive domains like recommendation systems and information retrieval are used such as NDCG and Hit Rate.
- generation quality: can evaluate different aspects like relevance and harmfulness if it’s unlabeled content or accuracy for labeled content.
focuses on three primary quality scores and four abilities
- Quality scores include measuring context relevance (i.e., the precision and specificity of retrieved context), answer faithfulness (i.e., the faithfulness of answers to the retrieved context), and answer relevance (i.e., the relevance of answers to posed questions).
- four abilities that help measure the adaptability and efficiency of a RAG system: noise robustness, negative rejection, information integration, and counterfactual robustness.
Conclusion
参考资料
Retrieval Augmented Generation (RAG) for LLMs | Prompt Engineering Guide (promptingguide.ai)
论文参考:
Retrieval-Augmented Generation for Large Language Models: A Survey (Gao et al., 2023)
https://github.com/HKUST-AI-Lab/Awesome-LLM-with-RAG
https://github.com/horseee/Awesome-Efficient-LLM
https://github.com/XiaoxinHe/iclr2024_learning_on_graph
Coding Langchain: RAG From Scratch: Part 1 (Overview) - YouTube