几个基础图神经网络
GCN、GraphSAGE和GAT
GCN
- 公式:(I是单位矩阵)

- 聚合过程
度矩阵的作用主要是归一化。如下图,GCN聚合的过程实际上是将邻居节点信息相加。如节点1和节点2、节点3相连,矩阵相乘的结果是:节点1的特征=节点2+节点3+自己。

- GCN操作
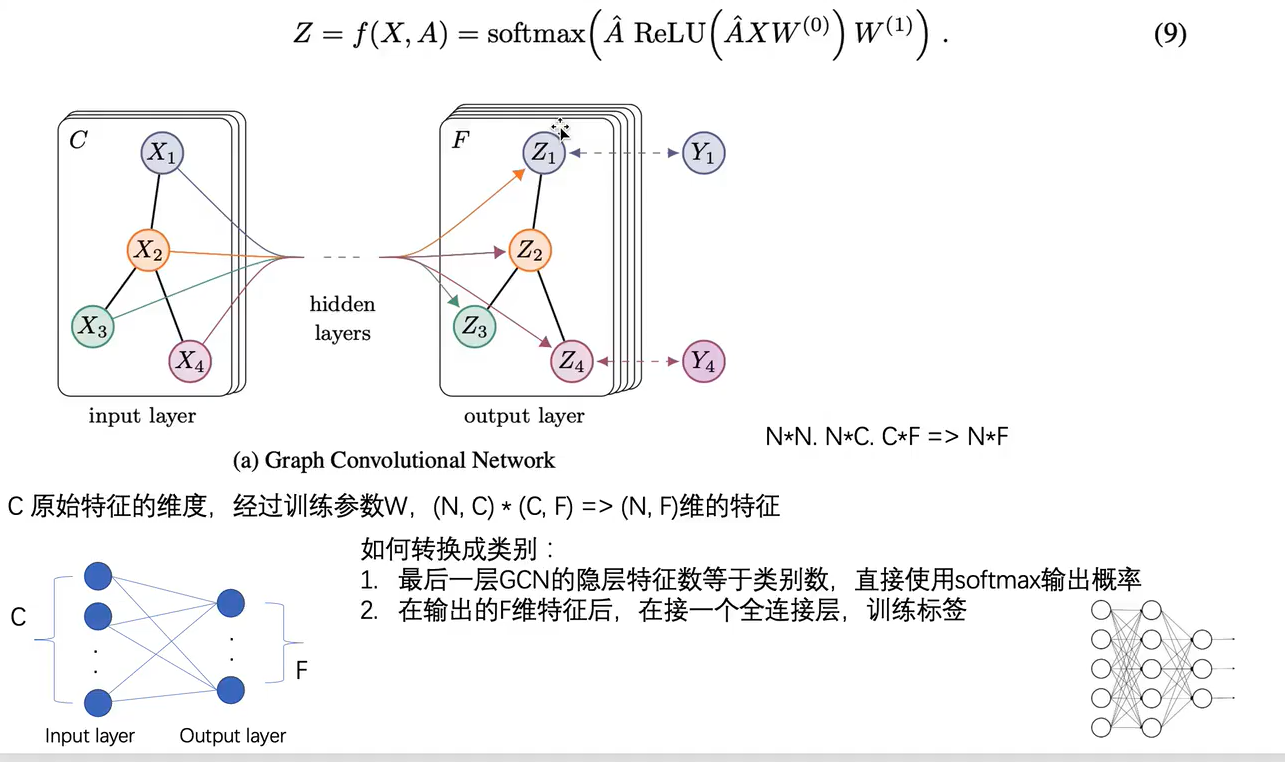
如下图是两层GCN卷积:(N,C)*(C,F) =>(N,F)
分类:1)最后输出的维度为分类的类数;2)不为分类的类数,只是作为一个特征提取器, 加上全连接层进行分类。
GraphSAGE(SAmple and aggreGatE)
提出归纳式的graph embedding方法,之前的graph embedding方法都是所有节点都在图中,对于没有
看到过的节点是不能处理的,这种叫做直推式方法。
而GraphSAGE这种归纳式的方法,可 以对于没见过的节点也生成embedding。
GraphSAGE不仅限于构建embedding,也通过聚合周围邻居节点的特征。
聚合

邻居采样
聚合邻居个数采用固定长度k。
当k<邻居总数时,直接neighbors = np.random.choice(neighbors,self.max_degree,replace=False)
当k>邻居数时,neighbors = np.random.choice(neighbors,self.max_degree,replace=True) (比如当邻居数是2,而要采样3个时,先将2个都放进来,然后再在2个邻居里面随机选一个凑三个)
作者发现该方法在K=2,即两层时可以达到好的表现。S1*S2<= 500(S1表示第一次采样的邻居数)
聚合函数
aggregator 需要满足的性质:
对称的
对于输入排列不变的
(即改变邻居节点输入的顺序,输出的结果不变)
三种
mean aggregator
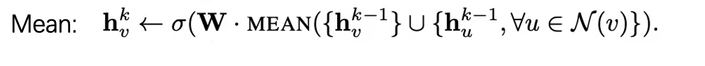
LSTM aggregator
LSTM本身是有顺序的,但是通过将输入节点随机排列,使得适用于无序集合。
容量大,表现好。
Pooling aggregator
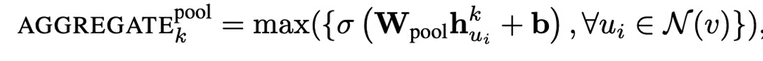
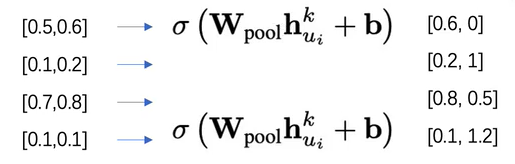
不仅可以使用max,使用其他的排列不变性函数都可以,如mean和max效果上是没有差异的。
通过W可以改变输出的维度。
GraphSAGE minibatch
和GCN使用全图不同的是,GraphSage用采样的方式,在minibatch下,可以不使用全图信息。使得在大规模图上训练变得可行。
算法如下图所示:

邻居采样:从第K-1层到第0层(从内到外)
以节点a为中心进行邻居采样。节点a所在层为第k层,此时k=2。聚合的总结点数为Sall = 1。
第k-1层,聚合第k层的Sk个邻居节点。此时B1层采样节点a(第2层)的S2个邻居,即三个邻居;采样的总节点数为Sall = Sall*S2 = 3.
第k-2层,聚合第k-1层的Sk-1个邻居。此时B0层采样B1层的S1个邻居,即B1层的三个节点的对应的两个邻居。总邻居数为Sall = Sall*S1 = 6.
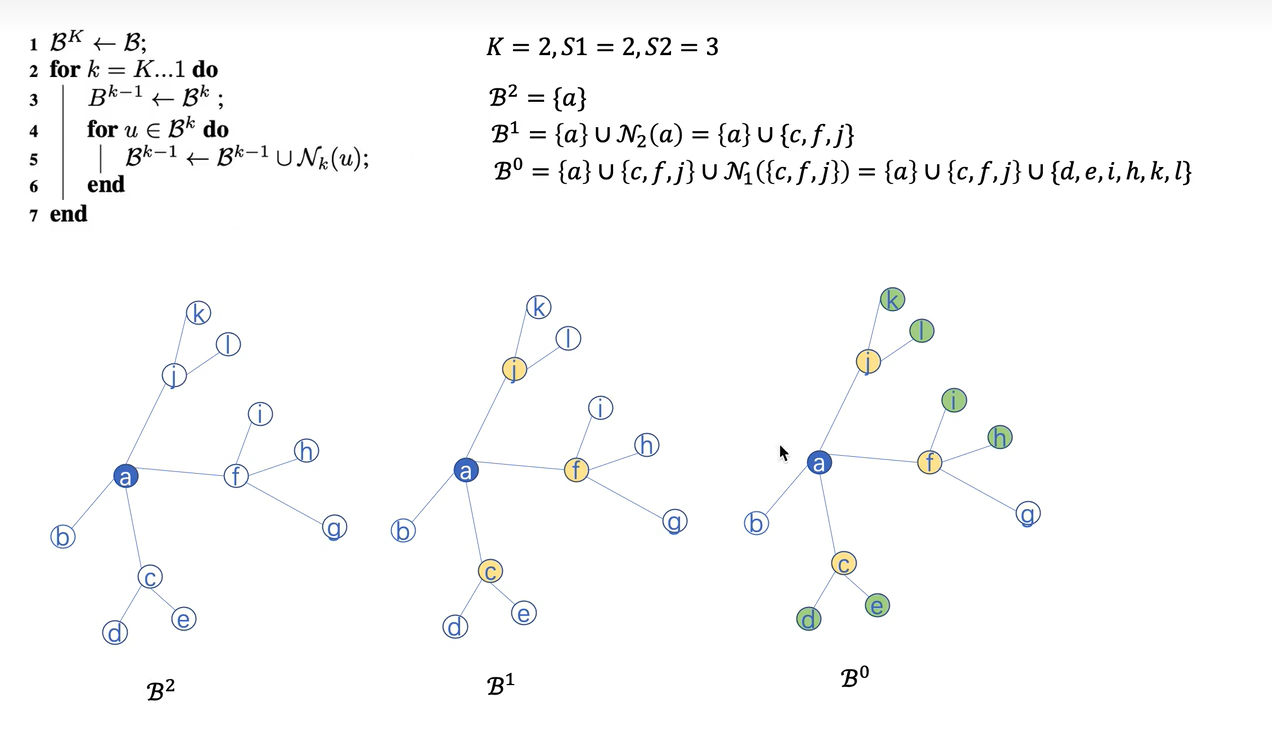
保存所有这些采样的节点作为后续聚合用。可以减少内存,在大图上用。
节点聚合:从第1层到第K层(从外到内)
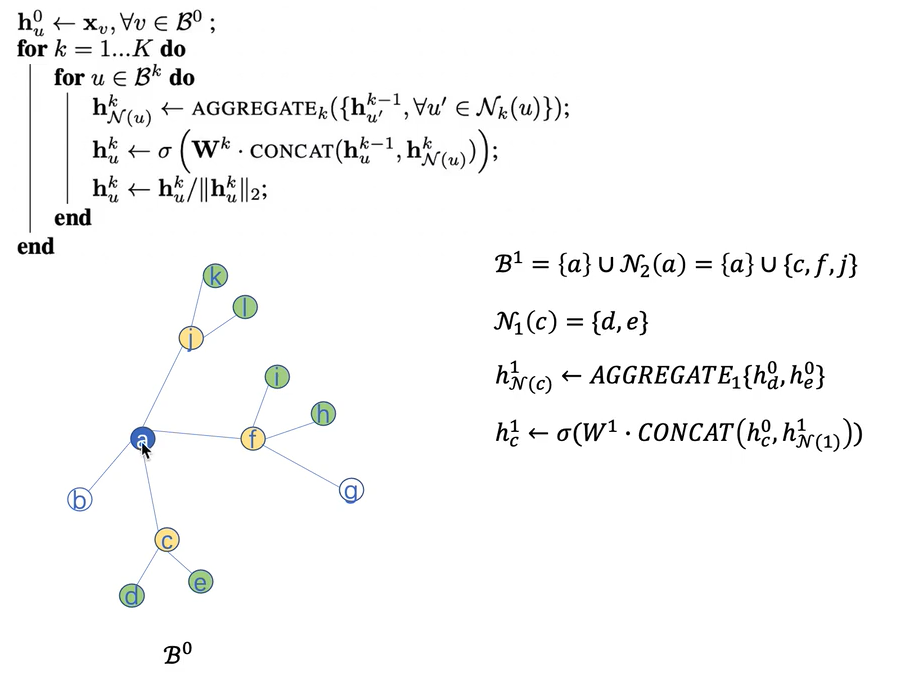
训练
训练的是GraphSage的权重函数W
经过GraphSage后,生成的embedding:Zu,求loss
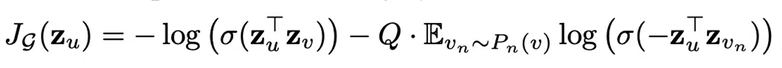
作者提出经过embedding之后,相近的节点应该有相似的表示,反之,区别较大的节点的表示应该很不同。zu为节点u的表示,应该使得相似的节点u和v,他们的表示$z_u^T z_v$乘积比较大,而不相似的乘积比较小=》该式的loss越小越好。
GAT(Graph Attention Networks)
- 公式:
N为邻居节点集合,||为concat,W为共享的权值
- 具体例子:

多头注意力机制
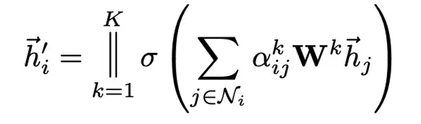
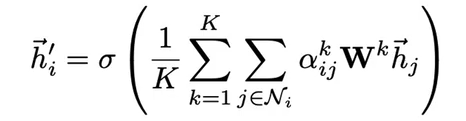
每一个注意力机制都学到节点的特征,然后将这K个拼接到一起作为最后的结果。
如果多头注意力机制在最后一层,用softmax预测,则拼接没必要,直接求平均。如果是接一个全连接层,拼接无所谓。
网络对比
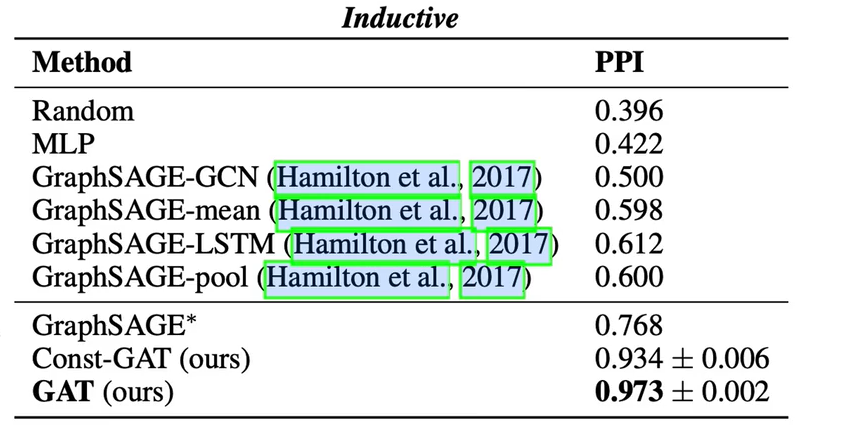
应用:
三者都可以用于半监督的任务。但是提出说GCN不能用于推理学习任务(即学习一张图,推荐没见过的另一张图),说是因为GCN的邻接矩阵的定义在两张图里面是不同的。(??)那GAT就可以是因为是动态的聚合邻居吗,即非需要全图。
代码
GCN
tkipf/pygcn: Graph Convolutional Networks in PyTorch (github.com)
数据集coras
pycharm调试
简单的跑一下默认数值 Test set results: loss= 0.7157 accuracy= 0.8320
GAT
github上仓库有对GAT代码进行更新,新的代码减少内存的占用:原本a_input是通过将所有节点concat;新的代码是:
1 | def _prepare_attentional_mechanism_input(self, Wh): |
- batch的实现
输入:[batch,node,feature]
adj: [batch,node,node]
关于GAT batch的实现,该仓库的issue中有讨论,并有提出一些解决方式。
我自己粗略的实现,在GraphAttentionLayer中修改:
1 | def forward(self, input, adj): |
一个博客的实现和我的思路类似:GAT(参数中加入batch)_2snoopy的博客-CSDN博客
该方法其实还是挺消耗内存的。
Diego999减轻内存占用并应用batch的实现:
How to implement batch training? · Issue #62 · Diego999/pyGAT (github.com)
实际中确实有减少内存占用,但是GAT本身的特质内存消耗比较大,可以去探索其他改进的GNN。
GraphSAGE
tensorflow版本:williamleif/GraphSAGE: Representation learning on large graphs using stochastic graph convolutions. (github.com)
pytorch实现(简洁版本):williamleif/graphsage-simple: Simple reference implementation of GraphSAGE. (github.com)