RAG with Gemma using wikipedia api
- 运行环境: windows11 CPU 12th Gen Intel(R) Core(TM) i5-12500H 运行内存16G
- Gemma:轻量级LLM
- 基于langchain实现,可视化使用smith.langchain
Setup
创建conda环境,安装依赖
- pytorch 2.1.2
- scikit-learn 1.4.0
- llama_cpp_python 0.2.52
- langchain 0.1.8
- langchain-community 0.0.21
- langchain-experimental 0.0.52
- tiktoken 0.6.0
- sentence-transformers 2.3.1
- numpy 1.26.4
- pandas 2.1.4
- wikipedia
下载gemma模型
模型下载:gemma-2b-it-q4_k_m.gguf · lmstudio-ai/gemma-2b-it-GGUF at main (huggingface.co)
实现
RAG 的过程概览
详细参考上一篇博客与Langchain demo overview
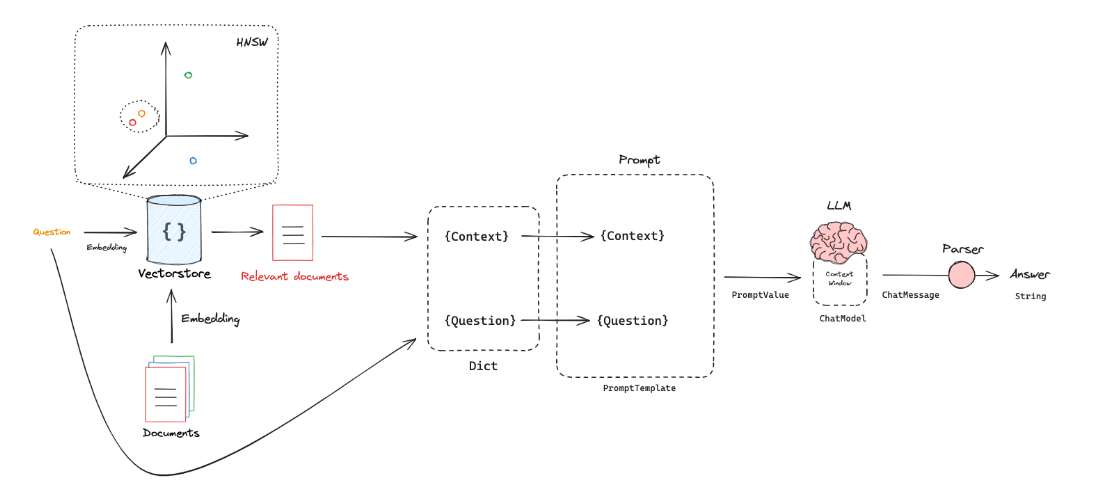
代码实现
使用Gemma,并基于wikipedia
1 | from langchain_community.retrievers import WikipediaRetriever |
注:代码运行过程中,访问维基百科,某些ip会被拒绝
运行输出
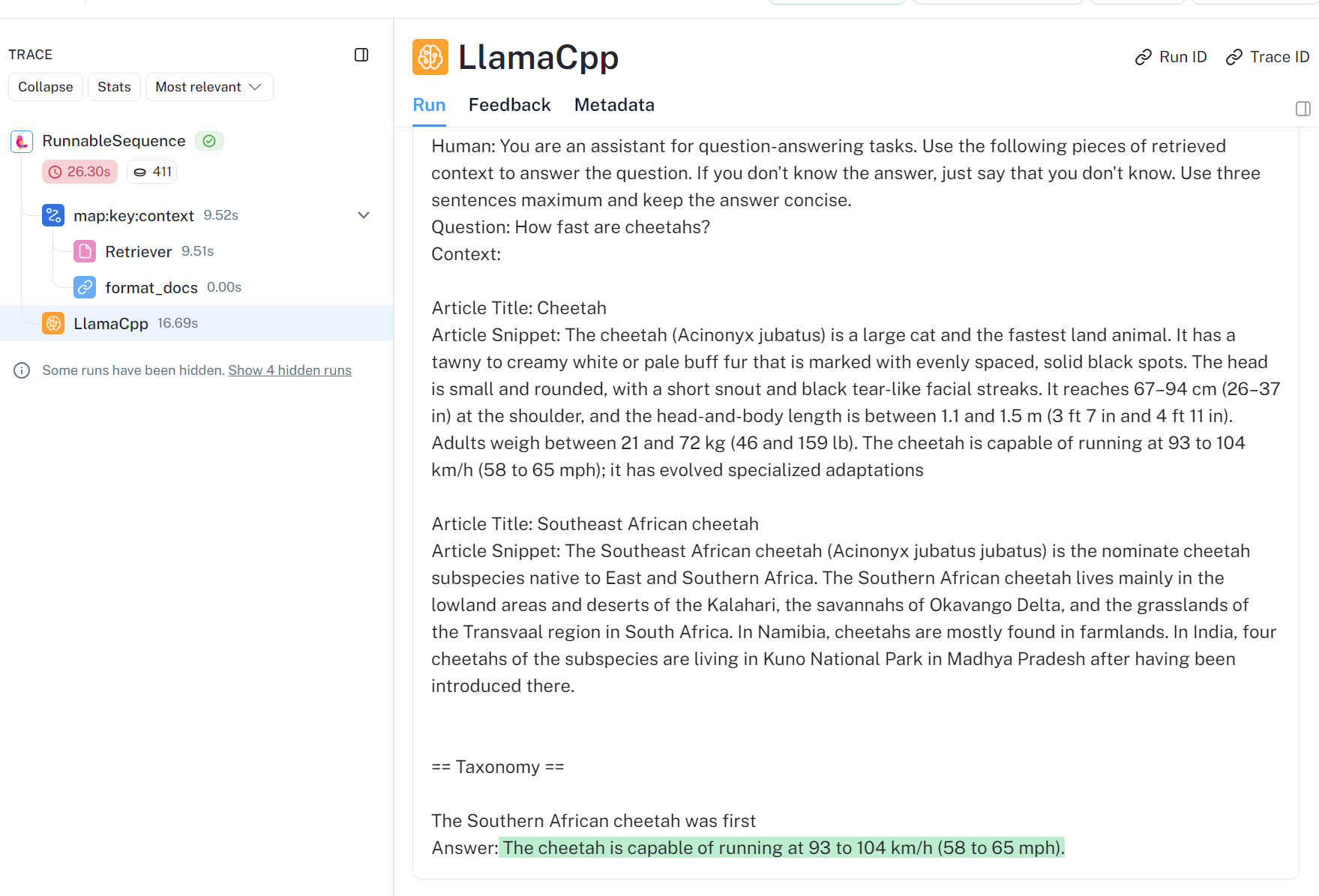
answer: The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90llama_model_loader: loaded meta data with 21 key-value pairs and 164 tensors from model/gemma-2b-it-q4_k_m.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = gemma
llama_model_loader: - kv 1: general.name str = gemma-2b-it
llama_model_loader: - kv 2: gemma.context_length u32 = 8192
llama_model_loader: - kv 3: gemma.block_count u32 = 18
llama_model_loader: - kv 4: gemma.embedding_length u32 = 2048
llama_model_loader: - kv 5: gemma.feed_forward_length u32 = 16384
llama_model_loader: - kv 6: gemma.attention.head_count u32 = 8
llama_model_loader: - kv 7: gemma.attention.head_count_kv u32 = 1
llama_model_loader: - kv 8: gemma.attention.key_length u32 = 256
llama_model_loader: - kv 9: gemma.attention.value_length u32 = 256
llama_model_loader: - kv 10: gemma.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.bos_token_id u32 = 2
llama_model_loader: - kv 13: tokenizer.ggml.eos_token_id u32 = 1
llama_model_loader: - kv 14: tokenizer.ggml.padding_token_id u32 = 0
llama_model_loader: - kv 15: tokenizer.ggml.unknown_token_id u32 = 3
llama_model_loader: - kv 16: tokenizer.ggml.tokens arr[str,256128] = ["<pad>", "<eos>", "<bos>", "<unk>", ...
llama_model_loader: - kv 17: tokenizer.ggml.scores arr[f32,256128] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 18: tokenizer.ggml.token_type arr[i32,256128] = [3, 3, 3, 2, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 19: general.quantization_version u32 = 2
llama_model_loader: - kv 20: general.file_type u32 = 15
llama_model_loader: - type f32: 37 tensors
llama_model_loader: - type q4_K: 109 tensors
llama_model_loader: - type q6_K: 18 tensors
llm_load_vocab: mismatch in special tokens definition ( 544/256128 vs 388/256128 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = gemma
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 256128
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 8192
llm_load_print_meta: n_embd = 2048
llm_load_print_meta: n_head = 8
llm_load_print_meta: n_head_kv = 1
llm_load_print_meta: n_layer = 18
llm_load_print_meta: n_rot = 256
llm_load_print_meta: n_embd_head_k = 256
llm_load_print_meta: n_embd_head_v = 256
llm_load_print_meta: n_gqa = 8
llm_load_print_meta: n_embd_k_gqa = 256
llm_load_print_meta: n_embd_v_gqa = 256
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 16384
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 2
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 8192
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 2B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 2.51 B
llm_load_print_meta: model size = 1.39 GiB (4.75 BPW)
llm_load_print_meta: general.name = gemma-2b-it
llm_load_print_meta: BOS token = 2 '<bos>'
llm_load_print_meta: EOS token = 1 '<eos>'
llm_load_print_meta: UNK token = 3 '<unk>'
llm_load_print_meta: PAD token = 0 '<pad>'
llm_load_print_meta: LF token = 227 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.06 MiB
llm_load_tensors: CPU buffer size = 1420.21 MiB
............................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CPU KV buffer size = 9.00 MiB
llama_new_context_with_model: KV self size = 9.00 MiB, K (f16): 4.50 MiB, V (f16): 4.50 MiB
llama_new_context_with_model: CPU input buffer size = 0.08 MiB
llama_new_context_with_model: CPU compute buffer size = 7.88 MiB
llama_new_context_with_model: graph splits (measure): 1
AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 0 |
Model metadata: {'general.name': 'gemma-2b-it', 'general.architecture': 'gemma', 'gemma.context_length': '8192', 'gemma.block_count': '18', 'gemma.attention.head_count_kv': '1', 'gemma.embedding_length': '2048', 'gemma.feed_forward_length': '16384', 'gemma.attention.head_count': '8', 'gemma.attention.key_length': '256', 'gemma.attention.value_length': '256', 'gemma.attention.layer_norm_rms_epsilon': '0.000001', 'tokenizer.ggml.model': 'llama', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '2', 'general.file_type': '15', 'tokenizer.ggml.eos_token_id': '1', 'tokenizer.ggml.padding_token_id': '0', 'tokenizer.ggml.unknown_token_id': '3'}
The cheetah is capable of running at 93 to 104 km/h (58 to 65 mph).
llama_print_timings: load time = 478.43 ms
llama_print_timings: sample time = 41.70 ms / 28 runs ( 1.49 ms per token, 671.48 tokens per second)
llama_print_timings: prompt eval time = 13944.05 ms / 378 tokens ( 36.89 ms per token, 27.11 tokens per second)
llama_print_timings: eval time = 1394.02 ms / 27 runs ( 51.63 ms per token, 19.37 tokens per second)
llama_print_timings: total time = 16688.10 ms / 405 tokens
Process finished with exit code 0
smith.langchain查看过程
retriever获取documnment,如下为两个,对应
wiki = WikipediaRetriever(top_k_results=2, doc_content_chars_max=550)
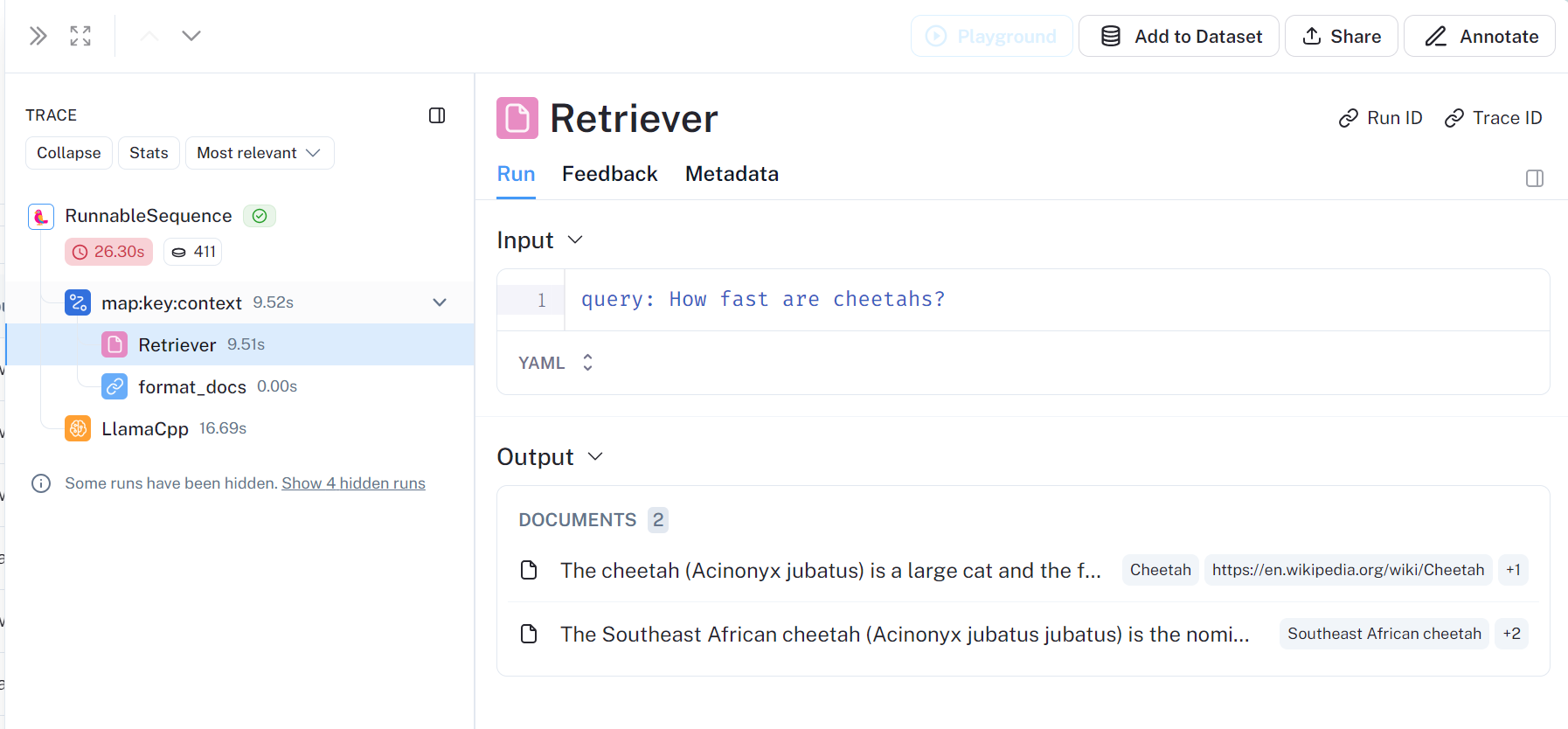
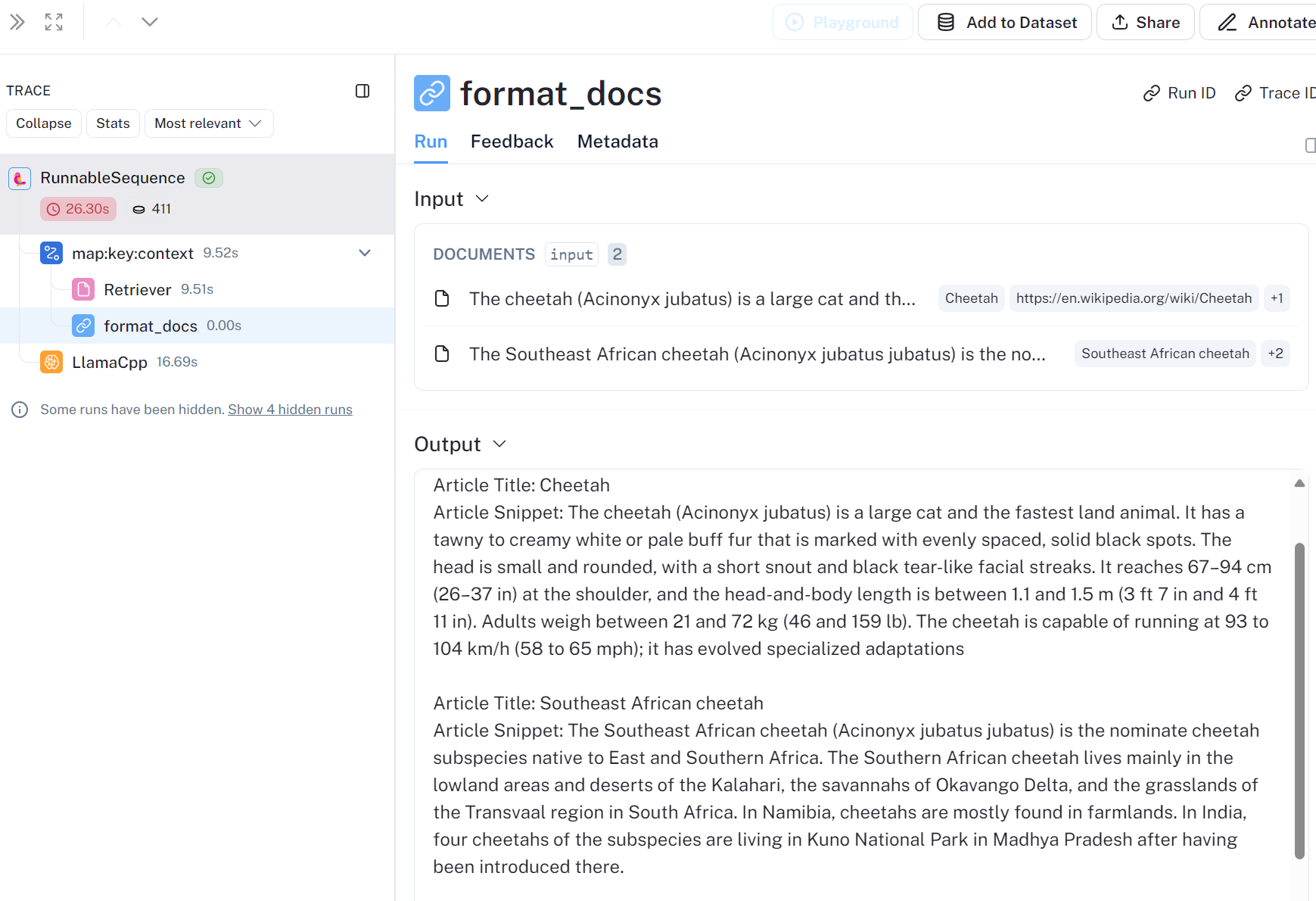
format_docs
将检索内容集成的提问与回答
进阶
增强RAG过程,提高检索有效性等
举例1
对检索到的文档进行后处理以压缩内容,这样源内容已经足够少,我们就不需要模型来引用特定的来源或跨度。
修改后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62def Retrieval_post_processing():
'''
post-process our retrieved documents to compress the content, so that the source content is already minimal enough that we don’t need the model to cite specific sources or spans.
Returns:
'''
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_community.embeddings import LlamaCppEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
wiki = WikipediaRetriever(top_k_results=3, doc_content_chars_max=1000)
rag_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}",
),
("human", "{question}"),
]
)
def format_docs(docs: List[Document]) -> str:
"""Convert Documents to a single string.:"""
formatted = [
f"Article Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}"
for doc in docs
]
return "\n\n" + "\n\n".join(formatted)
format = itemgetter("docs") | RunnableLambda(format_docs)
# subchain for generating an answer once we've done retrieval
answer = rag_prompt | llm | StrOutputParser()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=0,
separators=["\n\n", "\n", ".", " "],
keep_separator=False,
)
compressor = EmbeddingsFilter(embeddings=LlamaCppEmbeddings(model_path=model_path), k=3)
def split_and_filter(input) -> List[Document]:
docs = input["docs"]
question = input["question"]
split_docs = splitter.split_documents(docs)
stateful_docs = compressor.compress_documents(split_docs, question)
return [stateful_doc for stateful_doc in stateful_docs]
retrieve = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki) | split_and_filter
)
# docs = retrieve.invoke("How fast are cheetahs?")
# for doc in docs:
# print(doc.page_content)
# print("\n\n")
chain_4 = (
RunnableParallel(question=RunnablePassthrough(), docs=retrieve)
.assign(context=format)
.assign(answer=answer)
.pick(["answer", "docs"])
)
# Note the documents have an article "summary" in the metadata that is now much longer than the
# actual document page content. This summary isn't actually passed to the model.
print(chain_4.invoke("How fast are cheetahs?"))
应用RAG为其他任务赋能
如LLM+分类任务
搜索引擎赋能
https://github.com/miurla/morphic
参考
rag-from-scratch/rag_from_scratch_1_to_4.ipynb at main · langchain-ai/rag-from-scratch
rllm/examples/small_examples_with_LLM at main · rllm-project/rllm (github.com)