开源仓库问答机器人——基于LLM+Langchain+streamlit开发
应用场景说明
以Vchart为例,开发一个开源仓库问答机器人。
背景
VisActor是一个数据可视化渲染引擎,在开源社区中赢得了许多前端开发者的喜爱。你是VisActor项目中VChart框架的开发贡献者,每天会有很多用户向你提问关于仓库使用的问题。为了减轻运营开源项目的负担、同时更好的服务用户,你希望借助 LLM + Langchain 开发出一个智能问答机器人,机器人能够基于开源项目的用户文档来回答用户的常见问题。
需求说明
VChart智能问答机器人需提供可视化交互界面供开发者遇到问题时使用,用户典型问题如下:
1.框架介绍类: 介绍一下VChart的图表,它都由哪些部分组成。
2.功能使用类: VChart怎么下载?如何使用VChart配置出相关性散点图?
3.场景咨询类: 我发现如果数字的小数点位数较长时很不美观,有没有办法控制标签显示的小数位数的长度?
系统需要参考用户文档中的内容,定位到最关联的信息并通过大模型生成相应的回答,必要时可以输出代码/图片等多模态数据以更好的回答用户问题。
功能目标
- [ ]
能基于框架的使用文档回答用户提问,提供完整、符合逻辑的回答 - [ ]
具备简答的可视化交互界面 - [ ] 具有多模态回复能力
目前实现的效果
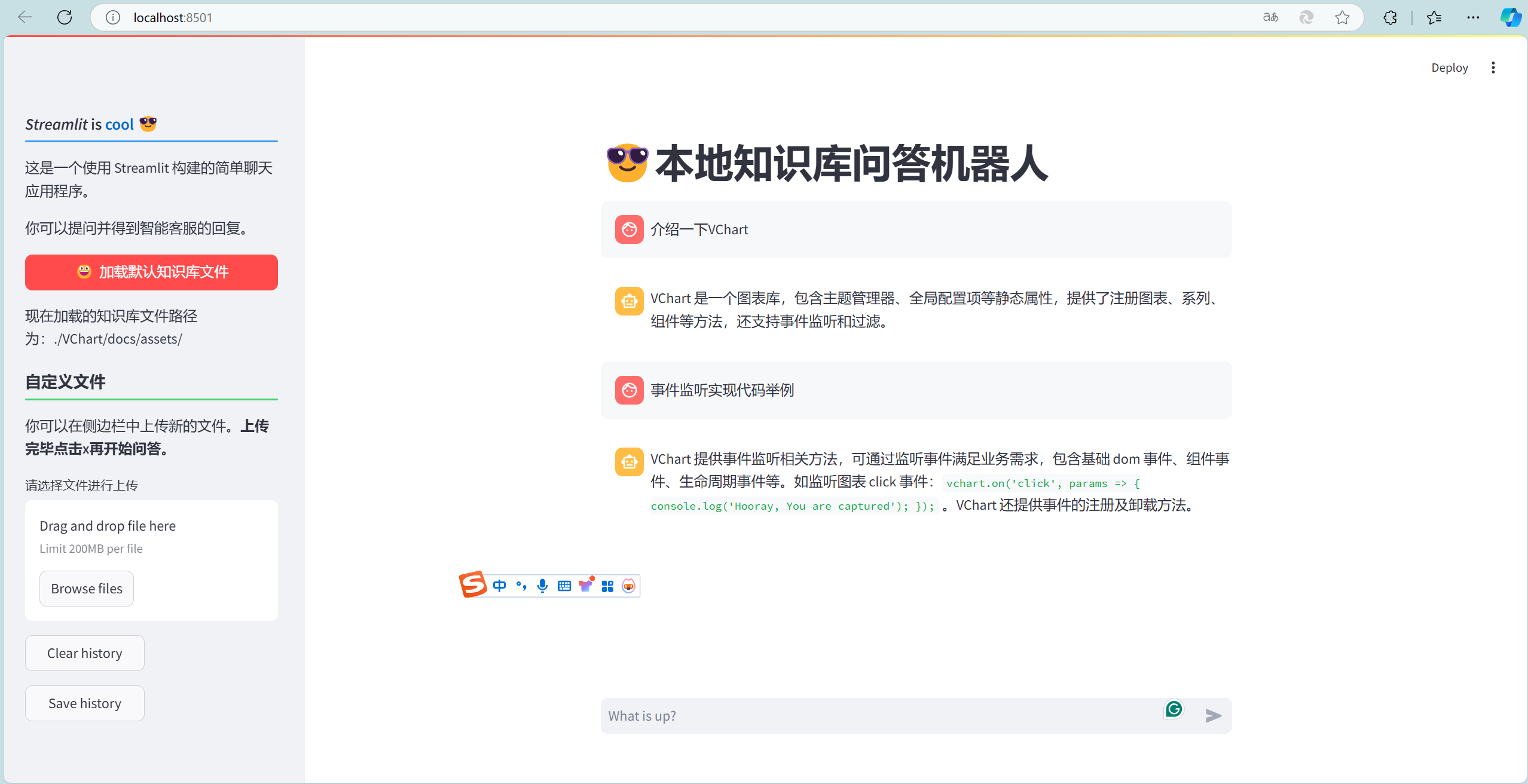
具体实现
项目目录
1 | OpenSourceChatbot |
LLM调用
通过API调用平台的大模型,实现在本地cpu环境即可运行。
langchain封装了很多大模型的调用。
以下以使用豆包大模型为例。
- 豆包大模型配置了和openai一样的接口,因此可以直接使用langchain的openai接口。
- 注册火山引擎的账号,选择特定的模型,获取模型各项配置:apikey, baseurl, model_id。
- 使用langchain调用llm。
debug and trace
使用langchainSmith可视化界面与交互
使用Streamlit实现网页可视化,使用langchain调用LLM。
文件命名为app.py。
各个组件
库导入
1 | import streamlit as st |
配置日志输出
1 | logger.add("app.log", rotation="1 week", compression="zip") # 自动按周滚动并压缩旧日志 |
将对话历史保存到本地
1 | def _history_to_disk(): |
传递构建本地知识库的文件并构造RAG链
streamlit的session_state可以存储会话状态。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def updatefiles(newdir):
st.session_state.basedir = newdir
msg = st.toast('building vectorstore...')
st.session_state.chatbot = ChatbotWithRetrieval(st.session_state.basedir)
msg.toast('done!', icon='🎉')
# 初始化RAG Chain
rag_prompt = hub.pull("rlm/rag-prompt")
# logger.info(rag_prompt)
st.session_state.rag_chain = (
{"context": st.session_state.chatbot.multiQueryRetriver | st.session_state.chatbot.format_docs, "question": RunnablePassthrough()}
#{"context": st.session_state.chatbot.retriever|st.session_state.chatbot.format_docs, "question": RunnablePassthrough()}
| rag_prompt
| st.session_state["llm"]
| StrOutputParser()
)
界面设置
- 标题
1
st.title(":sunglasses:本地知识库问答机器人")
初始化LLM
1 | if "llm" not in st.session_state: |
边栏设计与各项操作按钮
- 选择加载默认的知识库
- 支持自定义上传文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47with st.sidebar:
st.subheader("_Streamlit_ is :blue[cool] :sunglasses:",divider=True)
st.write("这是一个使用 Streamlit 构建的简单聊天应用程序。")
st.write("你可以提问并得到智能客服的回复。")
if st.button("加载默认知识库文件", icon="😃", use_container_width=True, type="primary"):
with st.status("preparing"):
st.session_state.basedir = "./VChart/docs/assets/"
# st.session_state.basedir = "./API/" #测试
updatefiles(st.session_state.basedir)
wn = st.session_state.basedir if "basedir" in st.session_state else 'None'
line = st.write(f"现在加载的知识库文件路径为:{wn}")
st.subheader("自定义文件", divider=True)
st.markdown("你可以在侧边栏中上传新的文件。**上传完毕点击x再开始问答。**")
# 文件上传
uploaded_file = st.file_uploader("请选择文件进行上传", type=None)
# 检查是否有文件上传
if uploaded_file is not None:
now = datetime.datetime.now().strftime("%Y%m%dT%H%M%S")
newdir = f"./upload/{now}/"
if not os.path.isdir(newdir):
os.makedirs(newdir)
# 获取文件字节内容
file_bytes = uploaded_file.read()
# 将文件保存到本地
save_path = f"{newdir}/{uploaded_file.name}"
with open(save_path, "wb") as f:
f.write(file_bytes)
# 显示文件信息
with st.expander("文件信息",expanded=True):
st.success(f"文件已保存到: {save_path}")
st.write(f"文件名: {uploaded_file.name}")
st.write(f"文件大小: {uploaded_file.size} 字节")
with st.status("preparing vectorstore..."):
updatefiles(newdir)
line = st.empty()
line.write(f"现在加载的知识库文件路径为:{st.session_state.basedir}")
### Memory clear
col1, col2 = st.columns([1, 1])
col1.button("Clear history", on_click=lambda: st.session_state.messages.clear(),
use_container_width=True,
help="Clear the conversation history for agent.",type="secondary")
### Memory save
col3, col4 = st.columns([1, 1])
col3.button("Save history", on_click=_history_to_disk, type="secondary", use_container_width=True)显示对话信息
1
2
3
4
5
6if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])用户对话输入与输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23if prompt := st.chat_input("What is up?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
# stream = client.chat.completions.create(
# model=st.session_state["llm"],
# messages=[
# {"role": m["role"], "content": m["content"]}
# for m in st.session_state.messages
# ],
# stream=True,
# ) ##历史所有message都提交了,费token
logger.info(st.session_state.basedir)
if "basedir" in st.session_state:
logger.info("RAG问答")
stream = st.session_state.rag_chain.stream(prompt)
else:
logger.info("llm问答")
stream = st.session_state.llm.stream(prompt)
response = st.write_stream(stream)
st.session_state.messages.append({"role": "assistant", "content": response})
本地知识库构建
- 优化1:前端选择加载本地知识库时,如果已经构建过了则从本地向量存储数据库检索,否则重新构建。由于项目文件比较多,重新构建一次费时,可以预先持久化存储。
- 优化2:通过批量操作加快嵌入和存储速率
具体实现
加载文档
开源仓库markdown文件居多,使用UnstructuredMarkdownLoader加载1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def load_documents(self, base_dir):
"""加载文档的函数,包括 pdf, txt, md, csv 等格式"""
documents = []
paths = os.walk(base_dir)
cnt_md, cnt_pdf, cnt_txt, cnt_csv = 0, 0, 0, 0
for path, dir_lst, file_lst in tqdm(paths):
for file_name in file_lst:
file_path = os.path.join(path, file_name)
if file_name.endswith(".pdf"):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
cnt_pdf += 1
elif file_name.endswith(".docx") or file_name.endswith(".doc"):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
cnt_txt += 1
elif file_name.endswith(".txt"):
loader = TextLoader(file_path)
documents.extend(loader.load())
elif file_name.endswith(".csv"):
loader = CSVLoader(file_path, encoding='utf-8')
documents.extend(loader.load())
cnt_csv += 1
elif file_name.endswith(".md"):
# logger.info("processing markdown data...")
cnt_md += 1
loader = UnstructuredMarkdownLoader(file_path)
documents.extend(loader.load())
# elif file_name.endswith(".json"):
# loader = JSONLoader(file_path,jq_schema=".messages[].content",text_content=False)
# documents.extend(loader.load())
logger.info(f"Finished loading documents from {base_dir}. Total {len(documents)} documents.\n"
f"total {cnt_md} md files, total {cnt_pdf} pdf files, total {cnt_txt} txt files, total {cnt_csv} csv files")
return documents
文本分割
1 | logger.info("vectorstore does not exist, building from documents") |
文本嵌入
- 使用huggingface开源嵌入模型,预先将模型下载到本地
1
2
3
4
5
6
7
8
9
10
11logger.info("start loading embedding model")
model_name = r"F:/pycharm_project/pythonProject/LANGCHAIN/chatbot/hub/BAAI/bge-small-zh-v1.5"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
bge_embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
logger.info("finish loading embedding model")向量存储
使用chroma数据库。 - 原本只需要一步:
不传入persist_directory默认加载存储到内存中1
2
3
4
5
6self.vectorstore = Chroma.from_documents(
documents=all_splits, # 以分块的文档
embedding=bge_embeddings, # 嵌入模型
persist_directory=persist_directory, ##保存到本地磁盘
collection_name=default_collection,
) # 指定collection_name 现为了优化存储速率分开处理
选择持久化存储直接加载之前存储好的
1
2
3
4
5if os.path.exists(self.persist_directory) and self.base_dir == default_directory:
logger.info("loading vectorstore from persist directory")
# 从磁盘中加载数据
self.vectorstore = Chroma(persist_directory=self.persist_directory, embedding_function=bge_embeddings,collection_name=self.collection_name)重新构建:向量化并存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72# 使用并行处理批量向量化
embeddings = self.batch_vectorize(all_splits, bge_embeddings,batch_size=self.batchsz)
# 将嵌入存储到 Chroma
logger.info("start building Chroma vectorstore")
self.vectorstore = self.store_embeddings_in_batches(all_splits, embeddings, self.persist_directory, bge_embeddings,self.collection_name,batch_size=self.batchsz)
logger.info("finish building vectorstore")
def batch_vectorize(self, all_splits, bge_embeddings, batch_size=64):
"""批量向量化"""
save_path = f"./tmp_save/embeddings/{os.path.basename(os.path.dirname(self.base_dir))}.npy"
if os.path.exists(save_path):
logger.info("loading embeddings from disk...")
embeddings = np.load(save_path)
return embeddings
else:
logger.info("embedding documents...")
embeddings = []
for i in tqdm(range(0, len(all_splits), batch_size)):
# 计算当前批次的结束位置,防止超出范围
end_idx = min(i + batch_size, len(all_splits))
batch_docs = all_splits[i:end_idx]
try:
batch_embeddings = bge_embeddings.embed_documents([doc.page_content for doc in batch_docs if doc.page_content])
embeddings.extend(batch_embeddings)
except Exception as e:
logger.info(f"Error processing batch {i}: {e}")
os.makedirs(os.path.dirname(save_path), exist_ok=True)
np.save(save_path, embeddings)
logger.info("saved embeddings to disk")
return embeddings
def store_embeddings_in_batches(self, all_splits, embeddings, persist_directory, bge_embeddings, default_collection,
batch_size=64):
"""批量存储向量到 Chroma"""
# 初始化 Chroma 向量数据库
vectorstore = Chroma(embedding_function=bge_embeddings, persist_directory=persist_directory,
collection_name=default_collection)
logger.info(f"Starting to store embeddings into collection: {default_collection}")
# 批量存储向量
total_docs = len(all_splits)
batch_ids = [] # 只在初始化时定义一次
for i in tqdm(range(0, total_docs, batch_size)):
# 计算当前批次的结束位置,防止超出范围
end_idx = min(i + batch_size, len(all_splits))
batch_docs = all_splits[i:end_idx]
batch_embeddings = embeddings[i:end_idx]
# 构建批次的文档 ID,确保全局唯一
batch_ids = [f"doc_{i + j}" for j in range(len(batch_docs))] # 给每个文档一个唯一的 ID
# 提取每个 Document 对象的 page_content,确保传递纯文本
batch_texts = [doc.page_content for doc in batch_docs]
try:
# 将该批次存储到 Chroma
logger.info(f"Processing batch {i // batch_size + 1}/{(total_docs // batch_size) + 1} "
f"with {len(batch_docs)} documents (ID range: {batch_ids[0]} to {batch_ids[-1]})")
# 向 Chroma 添加文本和嵌入
vectorstore.add_texts(batch_texts, embeddings=batch_embeddings, ids=batch_ids,collection_name=default_collection)
###可能有加入限制 一到64+x就退出了
except Exception as e:
logger.error(f"Error processing batch {i}: {e}")
continue # 继续处理下一个批次
# 持久化数据到磁盘
try:
vectorstore.persist()
logger.info(f"Persisted embeddings to {persist_directory}")
except Exception as e:
logger.error(f"Error during persistence: {e}")
# 返回存储后的 vectorstore 实例
return vectorstoreretriever
- 普通retriever
- multiQueryRetriever
1
2
3
4
5
6
7
8
9
10# 设置Retrieval Chain
self.retriever = self.vectorstore.as_retriever(search_kwargs={"k": 2})
# 实例化一个MultiQueryRetriever
## llm
self.llm = ChatOpenAI(
model=os.environ["LLM_MODELEND"],
temperature=0.5,
)
self.multiQueryRetriever = MultiQueryRetriever.from_llm(retriever=self.vectorstore.as_retriever(search_kwargs={"k": 2}), llm=self.llm)
启动
命令行运行1
streamlit run app.py
完整代码
app.py
1 | #!/usr/bin/env python |
retrieve.py
1 | #!/usr/bin/env python |
待优化的问题
- chroma数据库持久化存储过程中一到第96左右就卡住
- 多模态索引与输出
- openclip embedding
- glm-4v