zero-shot
Zero-shot is the natural best-case scenario for a model as it means we require zero training samples before shifting it to a new domain or task.
zero-shot是一个模型的自然最佳情况,因为这意味着我们将其迁移到新的领域或者任务时需要零个训练样本
动机
Sota的CV模型在特定的任务和数据集中表现良好,但是不能很好的泛化,他们无法处理在他们已经训练过的领域之外的新的类别或者图片。收集足够大的标记数据集以使用传统方法对这些专业用例的CV模型进行微调可能非常困难。
理想情况下,CV模型应该学习图像的内容,而不是过分关注最初训练理解的特定标签。比如,对于狗的图像,模型应该理解“狗在图像中”,当然那,如果它能理解背景中有树木、现在在白天、狗在草地上,那将更加有用。
分类训练的结果恰恰与该理想情况相反。模型学习将狗的internal representation放到相同的“狗向量空间”,将猫的放到相同的“猫向量空间”。他们关注的点在于图片是否与类匹配的yes or no。
重新训练分类模型是一种选择,但是需要大量的时间和成本投入:收集一个分类数据集和模型训练过程本身。
N-shot和Zero-shot
N-shot learning
Here we define N as the number of samples required to train a model to begin making predictions in a new domain or on a new task.
定义N为 为了在新领域或者新任务进行预测 而需要用于训练一个模型的样本数量。
如今,许多SotA模型都是在ResNet或BERT等用大量数据上进行预训练的。然后针对特定任务和领域对这些预训练模型进行微调。例如,可以使用 ImageNet 对 ResNet 模型进行预训练,然后针对服装分类进行微调。
像 ResNet 和 BERT 这样的模型被称为“N-shot”learner,因为我们需要许多训练样本才能在最后的微调步骤中达到可接受的性能。
只有当我们有计算、时间和数据允许我们微调模型时,N-shot learning才有可能。理想情况下,我们希望最大限度地提高模型性能,同时最小化N-shot要求。即提出Zero-shot。
zero-shot
zero-shot是一个模型的自然最佳情况,因为这意味着我们将其迁移到新的领域或者任务时需要零个训练样本。
Zero-shot实现
OpenAI的CLIP已经证明自己是一个非常灵活的分类模型,通常需要zero的再训练。
Contrastive Language-I mage Pretraining (CLIP) 是 OpenAI 于 2021 年发布的一个主要基于transformer的模型 [1]。
我们在这里使用的 CLIP 版本包括一个用于编码文本嵌入的文本转换器和一个用于编码图像嵌入的视觉转换器 (ViT)。
两种 CLIP 模型都在预训练期间进行了优化,以对齐向量空间中的相似文本和图像。它通过获取图像文本对 (image-text pairs )并在向量空间中将其输出向量推近,同时分离非对(non-pairs)的向量来实现这一点。
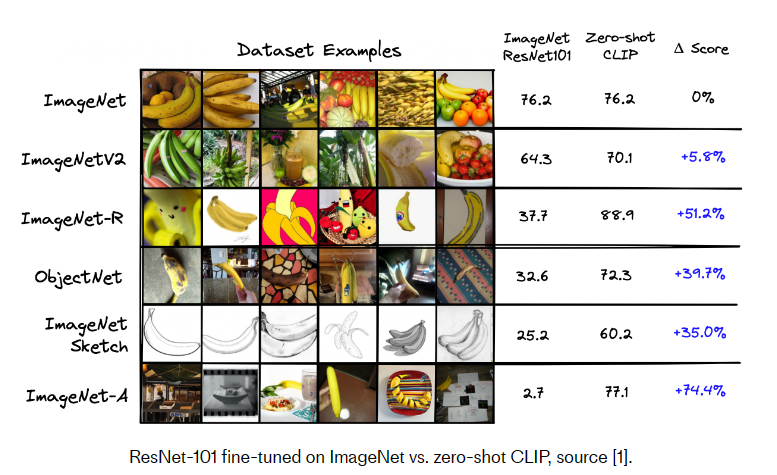
它与典型的分类模型区别开来有几个原因。首先,OpenAI在一个由4亿文本图像对组成的庞大数据集上对其进行了训练,这些数据集是从互联网上抓取的。
这里有三个主要好处:
- CLIP只需要图像-文本对,而不是特定的类标签,这要归功于contrastive而不是classification的训练功能。在当今以社交媒体为中心的世界中,这种类型的数据非常丰富。
- 大数据集大小意味着 CLIP 可以对图像中显示的一般文本概念建立深刻的理解。
- 文本描述符通常描述图像的各种特征,而不仅仅是一个特征。这意味着可以构建图像(和文本)的更全面的表示。
CLIP的这些优点是导致其出色的zero-shot性能的主要因素。
数据对比:
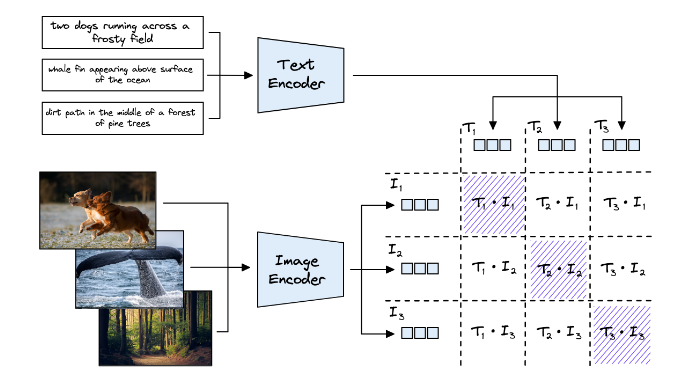
zero-shot classification
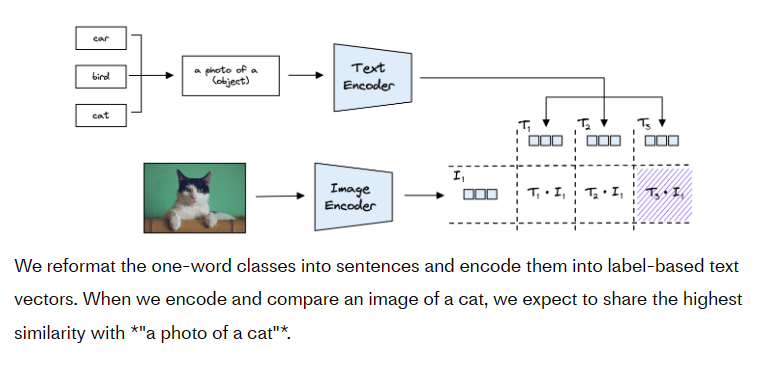
这些“类”中的每一个都作为向量从文本编码器分别输出为T1,T2和T3。给定一张猫的照片,我们使用 ViT 模型对其进行编码以创建矢量我I1.当我们用余弦相似性计算这些向量的相似性时,我们期望sim(T3,I1)返回最高分。
参考来源
Zero-shot Image Classification with OpenAI’s CLIP | Pinecone